 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePubLayNet: largest dataset ever for document layout analysis
Paper and Code

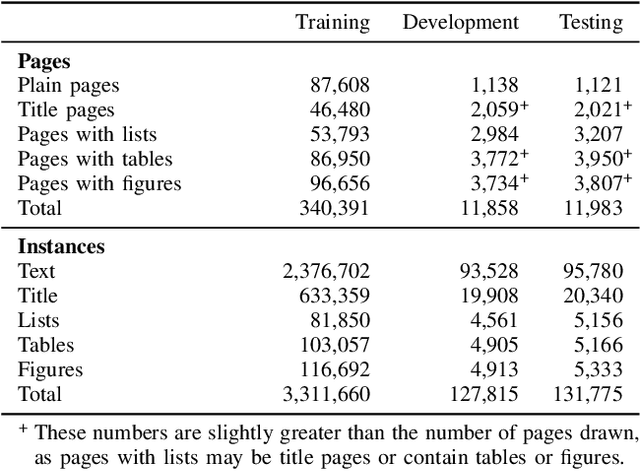

Recognizing the layout of unstructured digital documents is an important step when parsing the documents into structured machine-readable format for downstream applications. Deep neural networks that are developed for computer vision have been proven to be an effective method to analyze layout of document images. However, document layout datasets that are currently publicly available are several magnitudes smaller than established computing vision datasets. Models have to be trained by transfer learning from a base model that is pre-trained on a traditional computer vision dataset. In this paper, we develop the PubLayNet dataset for document layout analysis by automatically matching the XML representations and the content of over 1 million PDF articles that are publicly available on PubMed Central. The size of the dataset is comparable to established computer vision datasets, containing over 360 thousand document images, where typical document layout elements are annotated. The experiments demonstrate that deep neural networks trained on PubLayNet accurately recognize the layout of scientific articles. The pre-trained models are also a more effective base mode for transfer learning on a different document domain. We release the dataset (https://github.com/ibm-aur-nlp/PubLayNet) to support development and evaluation of more advanced models for document layout analysis.