 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding in Artificial Intelligence
Jan 17, 2021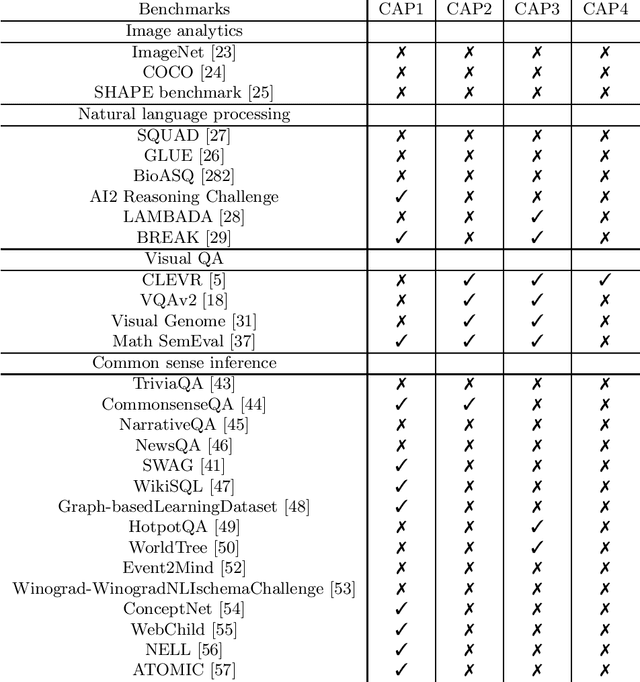
Current Artificial Intelligence (AI) methods, most based on deep learning, have facilitated progress in several fields, including computer vision and natural language understanding. The progress of these AI methods is measured using benchmarks designed to solve challenging tasks, such as visual question answering. A question remains of how much understanding is leveraged by these methods and how appropriate are the current benchmarks to measure understanding capabilities. To answer these questions, we have analysed existing benchmarks and their understanding capabilities, defined by a set of understanding capabilities, and current research streams. We show how progress has been made in benchmark development to measure understanding capabilities of AI methods and we review as well how current methods develop understanding capabilities.
Image-based table recognition: data, model, and evaluation
Jan 07, 2020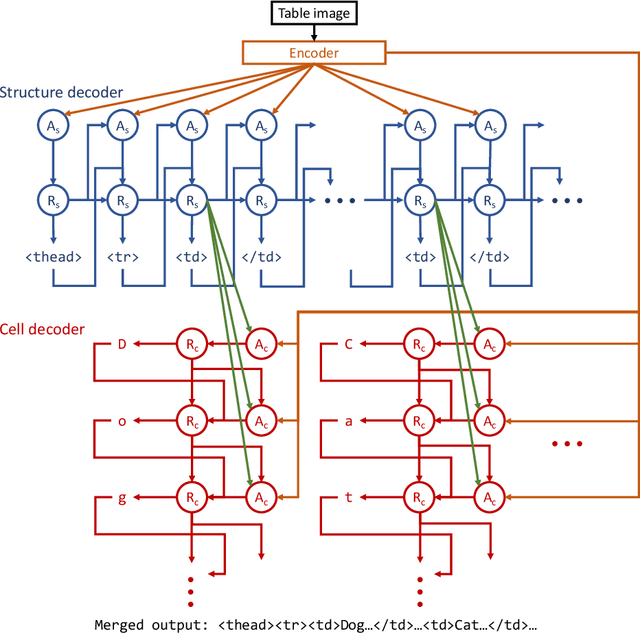
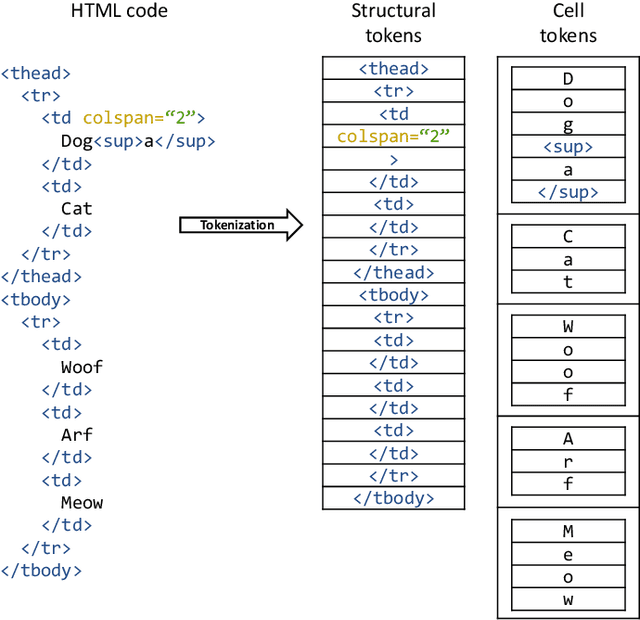
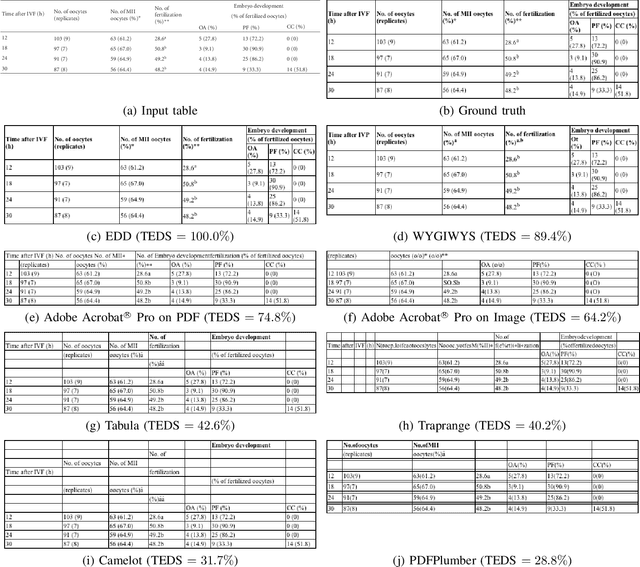

Important information that relates to a specific topic in a document is often organized in tabular format to assist readers with information retrieval and comparison, which may be difficult to provide in natural language. However, tabular data in unstructured digital documents, e.g., Portable Document Format (PDF) and images, are difficult to parse into structured machine-readable format, due to complexity and diversity in their structure and style. To facilitate image-based table recognition with deep learning, we develop the largest publicly available table recognition dataset PubTabNet (https://github.com/ibm-aur-nlp/PubTabNet), containing 568k table images with corresponding structured HTML representation. PubTabNet is automatically generated by matching the XML and PDF representations of the scientific articles in PubMed Central Open Access Subset (PMCOA). We also propose a novel attention-based encoder-dual-decoder (EDD) architecture that converts images of tables into HTML code. The model has a structure decoder which reconstructs the table structure and helps the cell decoder to recognize cell content. In addition, we propose a new Tree-Edit-Distance-based Similarity (TEDS) metric for table recognition. The experiments demonstrate that the EDD model can accurately recognize complex tables solely relying on the image representation, outperforming the state-of-the-art by 9.7% absolute TEDS score.
Global Locality in Event Extraction
Sep 11, 2019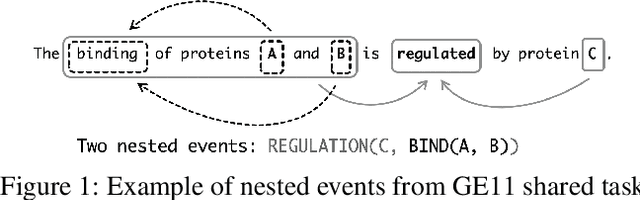
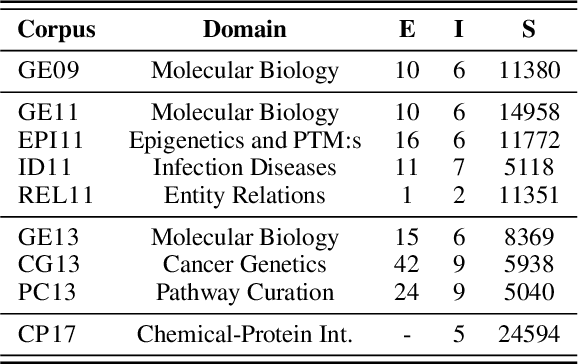
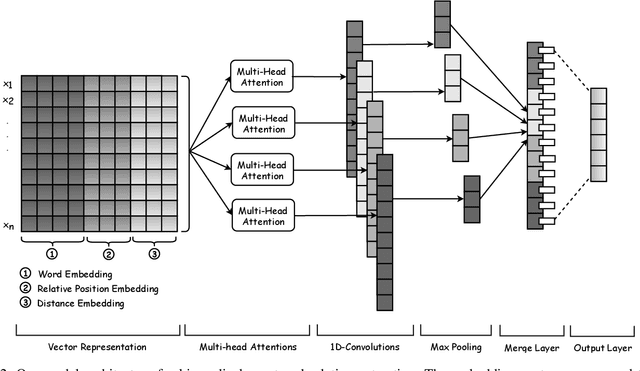
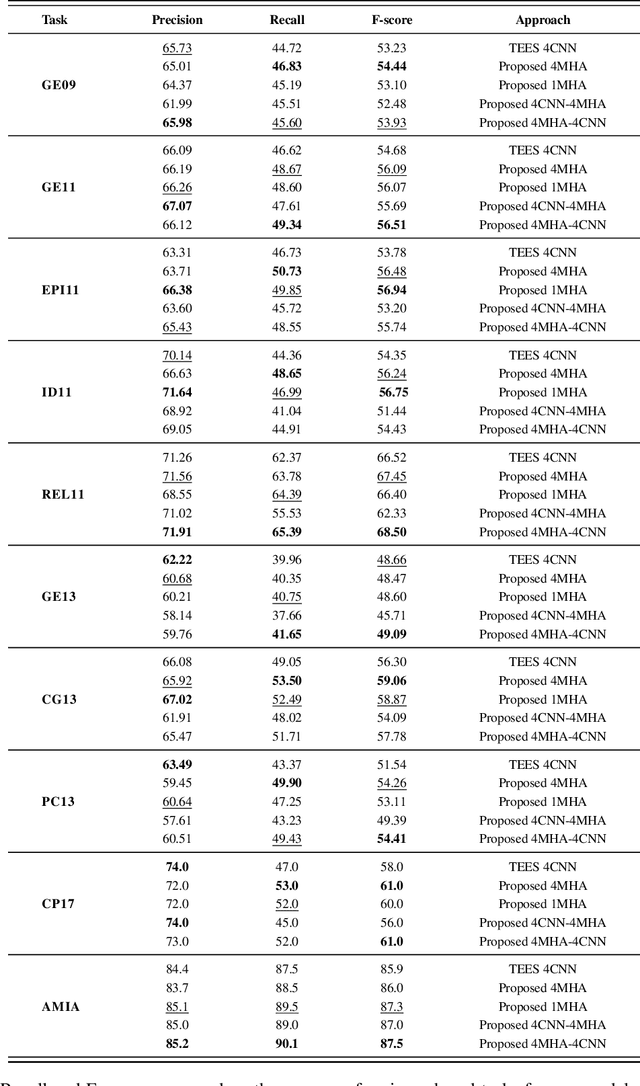
Due to the exponential growth of biomedical literature, event and relation extraction are important tasks in biomedical text mining. Most work in relation extraction detect a single entity pair mention on a short span of text, which is not ideal due to long sentences that appear in biomedical contexts. We propose an approach to both event and relation extraction, for simultaneously predicting relationships between all mention pairs in a text. Our model includes a set of multi-head attentions and convolutions, an adaptation of the transformer architecture, which offers self-attention the ability to strengthen dependencies among related elements, and models the interaction between features extracted by multiple attention heads. Experiment results demonstrate that our approach outperforms the state-of-the-art on a set of benchmark biomedical corpora including BioNLP 2009, 2011, 2013 and BioCreative 2017 shared tasks.
A Semantically Motivated Approach to Compute ROUGE Scores
Oct 20, 2017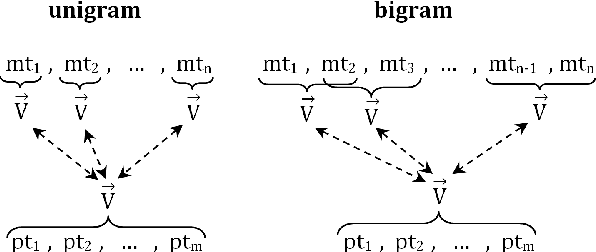
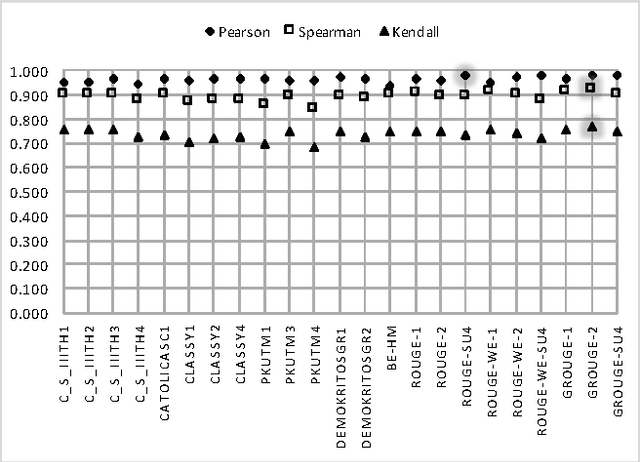
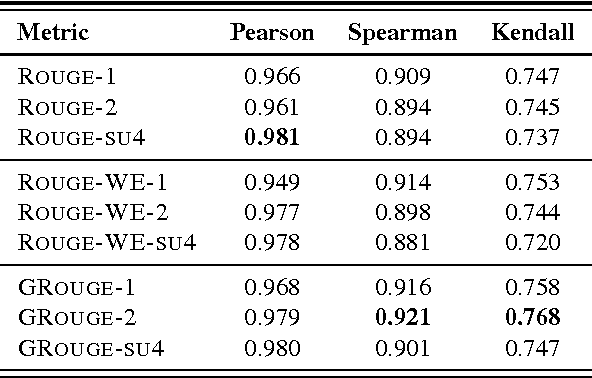
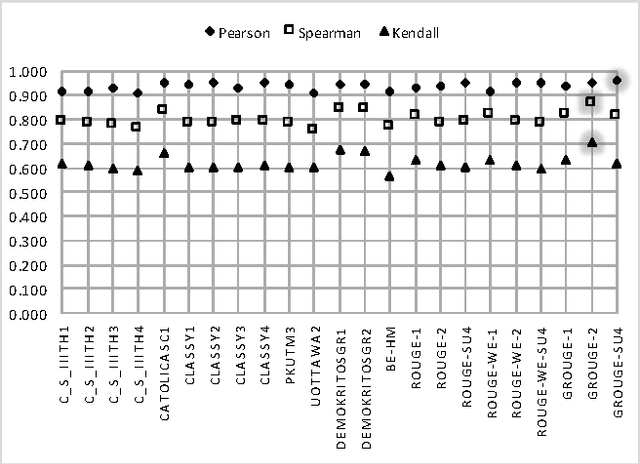
ROUGE is one of the first and most widely used evaluation metrics for text summarization. However, its assessment merely relies on surface similarities between peer and model summaries. Consequently, ROUGE is unable to fairly evaluate abstractive summaries including lexical variations and paraphrasing. Exploring the effectiveness of lexical resource-based models to address this issue, we adopt a graph-based algorithm into ROUGE to capture the semantic similarities between peer and model summaries. Our semantically motivated approach computes ROUGE scores based on both lexical and semantic similarities. Experiment results over TAC AESOP datasets indicate that exploiting the lexico-semantic similarity of the words used in summaries would significantly help ROUGE correlate better with human judgments.
On Improving Informativity and Grammaticality for Multi-Sentence Compression
May 07, 2016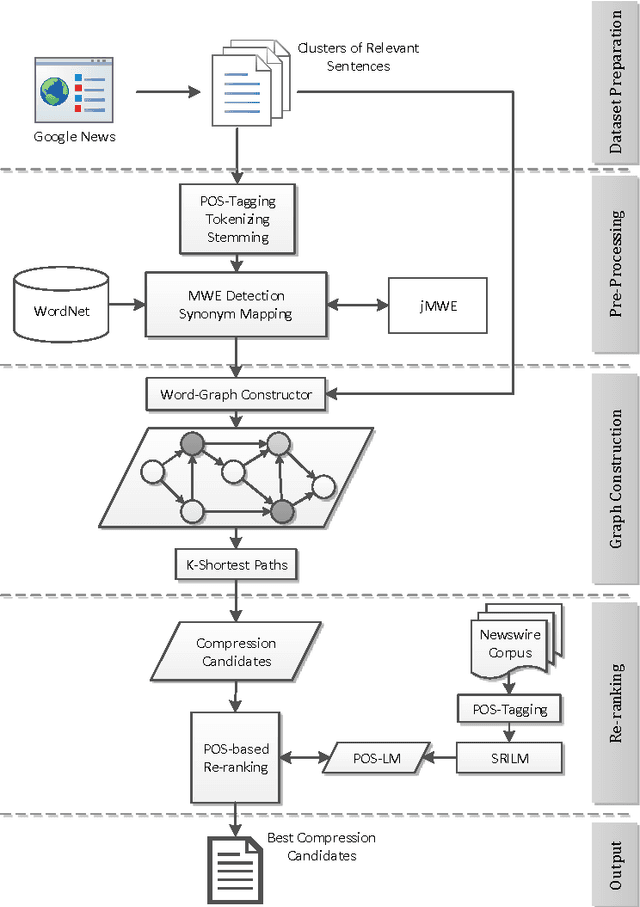
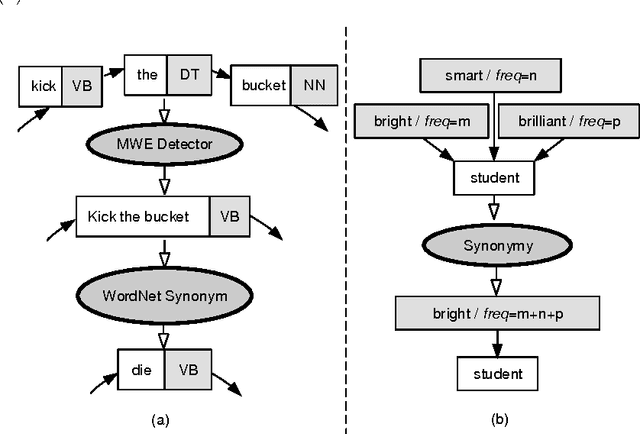
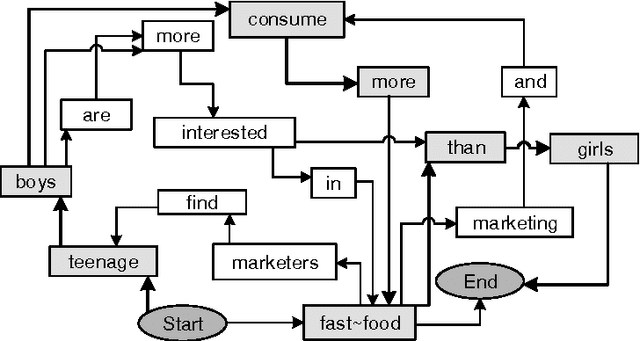
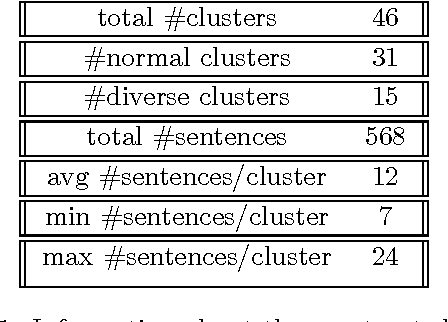
Multi Sentence Compression (MSC) is of great value to many real world applications, such as guided microblog summarization, opinion summarization and newswire summarization. Recently, word graph-based approaches have been proposed and become popular in MSC. Their key assumption is that redundancy among a set of related sentences provides a reliable way to generate informative and grammatical sentences. In this paper, we propose an effective approach to enhance the word graph-based MSC and tackle the issue that most of the state-of-the-art MSC approaches are confronted with: i.e., improving both informativity and grammaticality at the same time. Our approach consists of three main components: (1) a merging method based on Multiword Expressions (MWE); (2) a mapping strategy based on synonymy between words; (3) a re-ranking step to identify the best compression candidates generated using a POS-based language model (POS-LM). We demonstrate the effectiveness of this novel approach using a dataset made of clusters of English newswire sentences. The observed improvements on informativity and grammaticality of the generated compressions show that our approach is superior to state-of-the-art MSC methods.