 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSingle versus Multiple Annotation for Named Entity Recognition of Mutations
Jan 19, 2021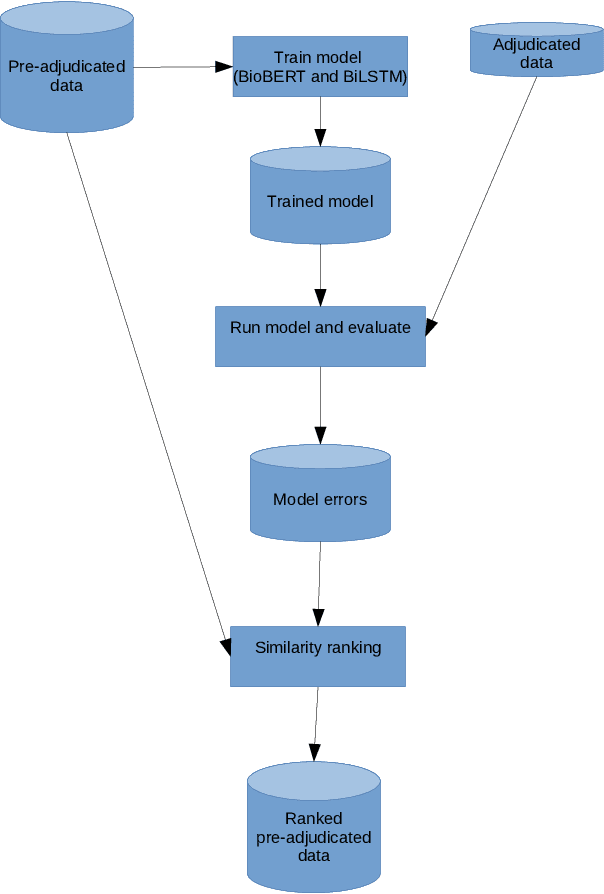
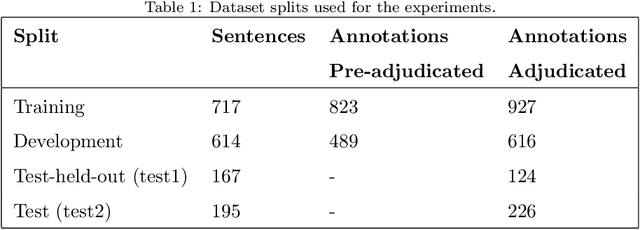
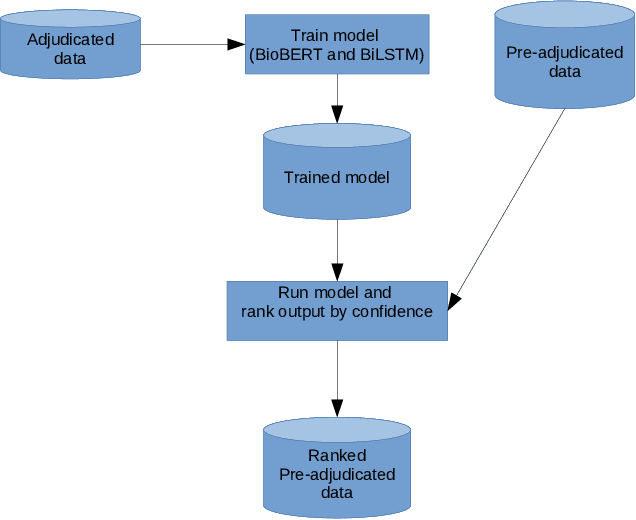
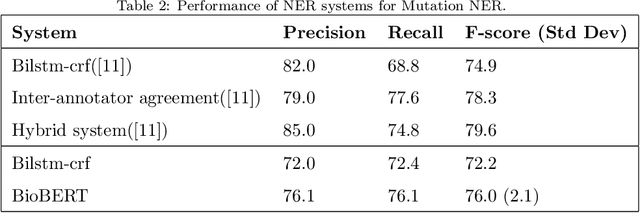
The focus of this paper is to address the knowledge acquisition bottleneck for Named Entity Recognition (NER) of mutations, by analysing different approaches to build manually-annotated data. We address first the impact of using a single annotator vs two annotators, in order to measure whether multiple annotators are required. Once we evaluate the performance loss when using a single annotator, we apply different methods to sample the training data for second annotation, aiming at improving the quality of the dataset without requiring a full pass. We use held-out double-annotated data to build two scenarios with different types of rankings: similarity-based and confidence based. We evaluate both approaches on: (i) their ability to identify training instances that are erroneous (cases where single-annotator labels differ from double-annotation after discussion), and (ii) on Mutation NER performance for state-of-the-art classifiers after integrating the fixes at different thresholds.
Understanding in Artificial Intelligence
Jan 17, 2021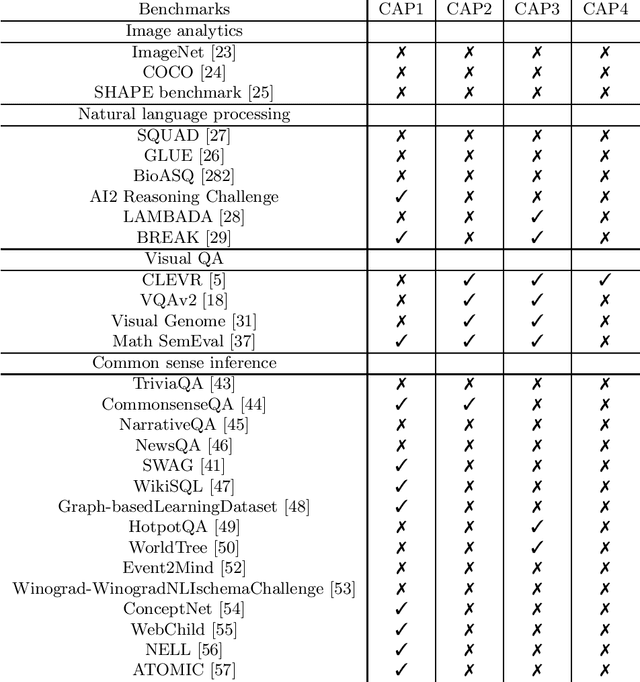
Current Artificial Intelligence (AI) methods, most based on deep learning, have facilitated progress in several fields, including computer vision and natural language understanding. The progress of these AI methods is measured using benchmarks designed to solve challenging tasks, such as visual question answering. A question remains of how much understanding is leveraged by these methods and how appropriate are the current benchmarks to measure understanding capabilities. To answer these questions, we have analysed existing benchmarks and their understanding capabilities, defined by a set of understanding capabilities, and current research streams. We show how progress has been made in benchmark development to measure understanding capabilities of AI methods and we review as well how current methods develop understanding capabilities.