 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA New Method for Cross-Lingual-based Semantic Role Labeling
Aug 28, 2024



Semantic role labeling is a crucial task in natural language processing, enabling better comprehension of natural language. However, the lack of annotated data in multiple languages has posed a challenge for researchers. To address this, a deep learning algorithm based on model transfer has been proposed. The algorithm utilizes a dataset consisting of the English portion of CoNLL2009 and a corpus of semantic roles in Persian. To optimize the efficiency of training, only ten percent of the educational data from each language is used. The results of the proposed model demonstrate significant improvements compared to Niksirt et al.'s model. In monolingual mode, the proposed model achieved a 2.05 percent improvement on F1-score, while in cross-lingual mode, the improvement was even more substantial, reaching 6.23 percent. Worth noting is that the compared model only trained two of the four stages of semantic role labeling and employed golden data for the remaining two stages. This suggests that the actual superiority of the proposed model surpasses the reported numbers by a significant margin. The development of cross-lingual methods for semantic role labeling holds promise, particularly in addressing the scarcity of annotated data for various languages. These advancements pave the way for further research in understanding and processing natural language across different linguistic contexts.
Efficient Design of Multi-group Multicast Beamforming via Reconfigurable Intelligent Surface
Dec 31, 2023



This paper considers a multi-group multicasting scenario facilitated by a reconfigurable intelligent surface (RIS). We propose a fast and scalable algorithm for the joint design of the base station (BS) multicast beamforming and the RIS passive beamforming to minimize the transmit power subject to the quality-of-service (QoS) constraints. By exploring the structure of the joint optimization problem, we show that this QoS problem can be broken into a BS multicast QoS subproblem and an RIS max-min-fair (MMF) multicast subproblem, which are solved alternatingly. In our proposed algorithm, we utilize the optimal multicast beamforming structure to obtain the BS beamformers efficiently. Furthermore, we reformulate the challenging RIS multicast subproblem and employ a first-order projected subgradient algorithm (PSA) to solve it, which yields closed-form updates. Simulation results show the efficacy of our proposed algorithm in performance and computational cost compared to other alternative methods.
A Semantically Motivated Approach to Compute ROUGE Scores
Oct 20, 2017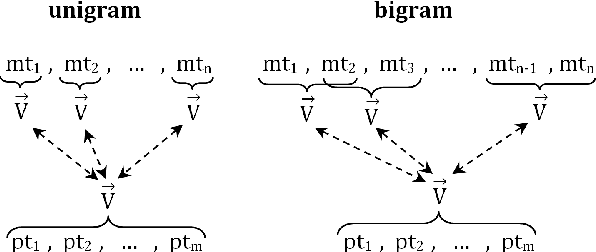
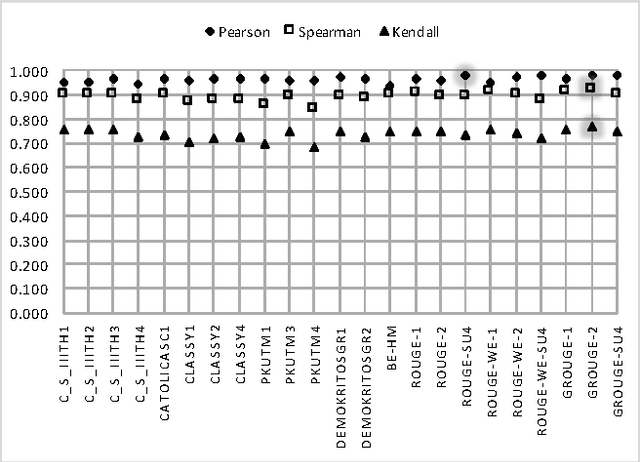
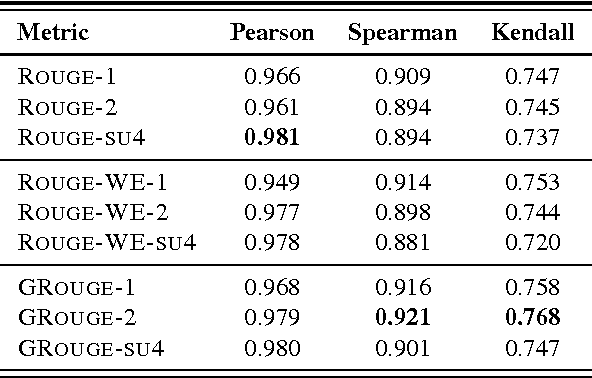
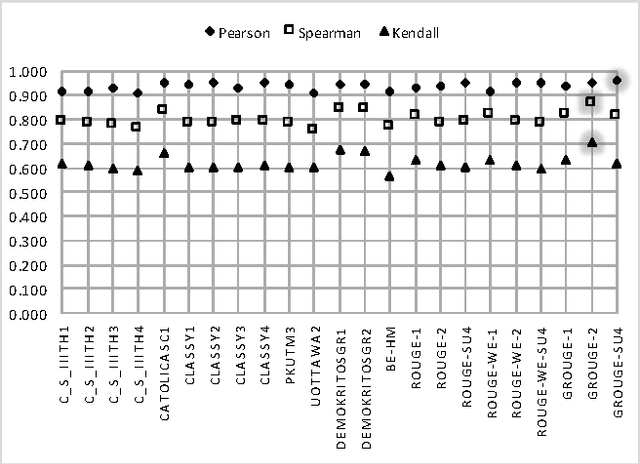
ROUGE is one of the first and most widely used evaluation metrics for text summarization. However, its assessment merely relies on surface similarities between peer and model summaries. Consequently, ROUGE is unable to fairly evaluate abstractive summaries including lexical variations and paraphrasing. Exploring the effectiveness of lexical resource-based models to address this issue, we adopt a graph-based algorithm into ROUGE to capture the semantic similarities between peer and model summaries. Our semantically motivated approach computes ROUGE scores based on both lexical and semantic similarities. Experiment results over TAC AESOP datasets indicate that exploiting the lexico-semantic similarity of the words used in summaries would significantly help ROUGE correlate better with human judgments.
On Improving Informativity and Grammaticality for Multi-Sentence Compression
May 07, 2016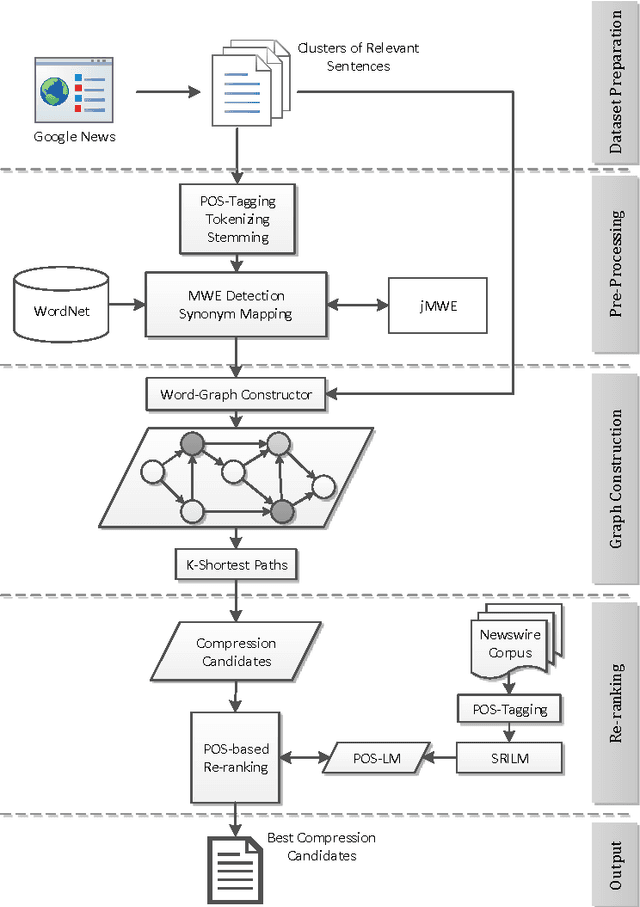
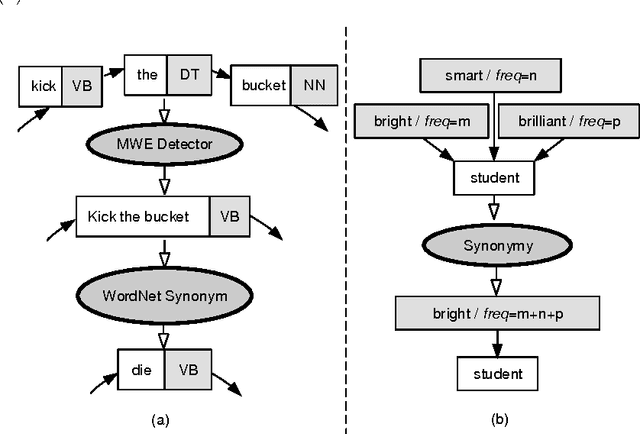
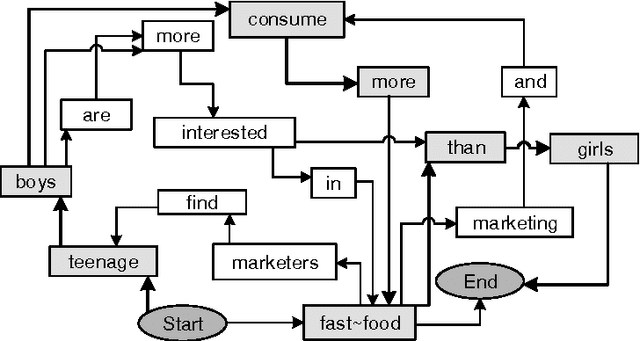
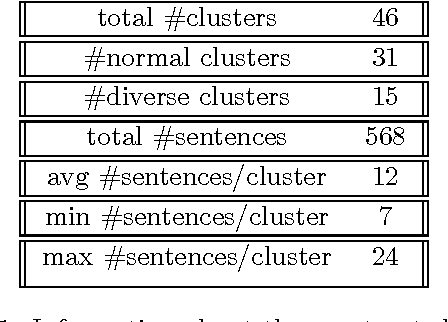
Multi Sentence Compression (MSC) is of great value to many real world applications, such as guided microblog summarization, opinion summarization and newswire summarization. Recently, word graph-based approaches have been proposed and become popular in MSC. Their key assumption is that redundancy among a set of related sentences provides a reliable way to generate informative and grammatical sentences. In this paper, we propose an effective approach to enhance the word graph-based MSC and tackle the issue that most of the state-of-the-art MSC approaches are confronted with: i.e., improving both informativity and grammaticality at the same time. Our approach consists of three main components: (1) a merging method based on Multiword Expressions (MWE); (2) a mapping strategy based on synonymy between words; (3) a re-ranking step to identify the best compression candidates generated using a POS-based language model (POS-LM). We demonstrate the effectiveness of this novel approach using a dataset made of clusters of English newswire sentences. The observed improvements on informativity and grammaticality of the generated compressions show that our approach is superior to state-of-the-art MSC methods.