 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA New Method for Cross-Lingual-based Semantic Role Labeling
Aug 28, 2024



Semantic role labeling is a crucial task in natural language processing, enabling better comprehension of natural language. However, the lack of annotated data in multiple languages has posed a challenge for researchers. To address this, a deep learning algorithm based on model transfer has been proposed. The algorithm utilizes a dataset consisting of the English portion of CoNLL2009 and a corpus of semantic roles in Persian. To optimize the efficiency of training, only ten percent of the educational data from each language is used. The results of the proposed model demonstrate significant improvements compared to Niksirt et al.'s model. In monolingual mode, the proposed model achieved a 2.05 percent improvement on F1-score, while in cross-lingual mode, the improvement was even more substantial, reaching 6.23 percent. Worth noting is that the compared model only trained two of the four stages of semantic role labeling and employed golden data for the remaining two stages. This suggests that the actual superiority of the proposed model surpasses the reported numbers by a significant margin. The development of cross-lingual methods for semantic role labeling holds promise, particularly in addressing the scarcity of annotated data for various languages. These advancements pave the way for further research in understanding and processing natural language across different linguistic contexts.
Persian Semantic Role Labeling Using Transfer Learning and BERT-Based Models
Jun 17, 2023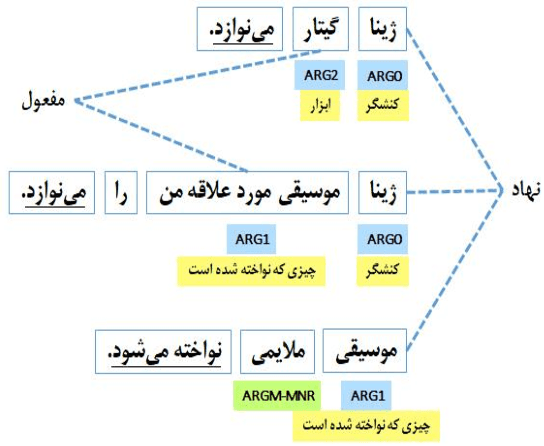

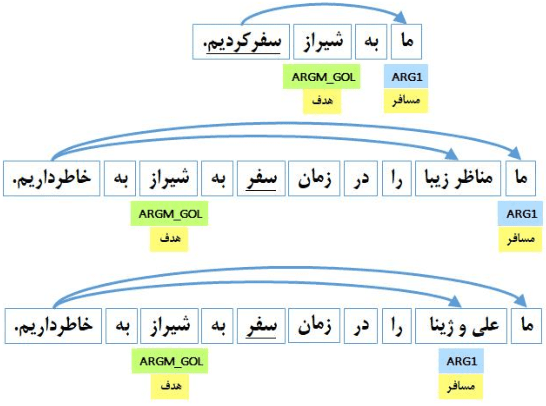

Semantic role labeling (SRL) is the process of detecting the predicate-argument structure of each predicate in a sentence. SRL plays a crucial role as a pre-processing step in many NLP applications such as topic and concept extraction, question answering, summarization, machine translation, sentiment analysis, and text mining. Recently, in many languages, unified SRL dragged lots of attention due to its outstanding performance, which is the result of overcoming the error propagation problem. However, regarding the Persian language, all previous works have focused on traditional methods of SRL leading to a drop in accuracy and imposing expensive feature extraction steps in terms of financial resources, time and energy consumption. In this work, we present an end-to-end SRL method that not only eliminates the need for feature extraction but also outperforms existing methods in facing new samples in practical situations. The proposed method does not employ any auxiliary features and shows more than 16 (83.16) percent improvement in accuracy against previous methods in similar circumstances.