 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Semantically Motivated Approach to Compute ROUGE Scores
Paper and Code
Oct 20, 2017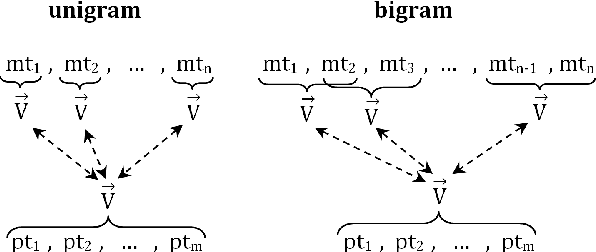
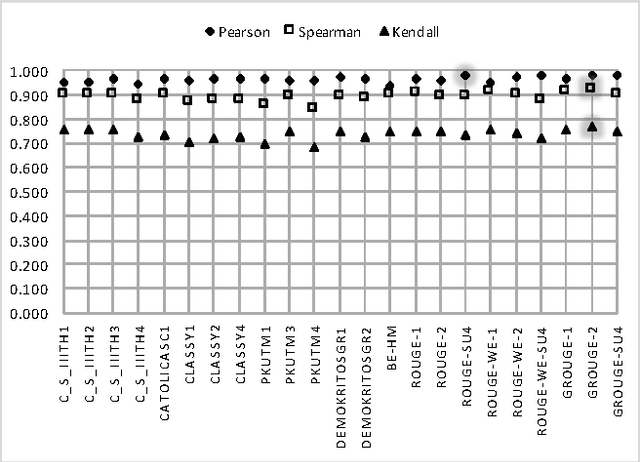
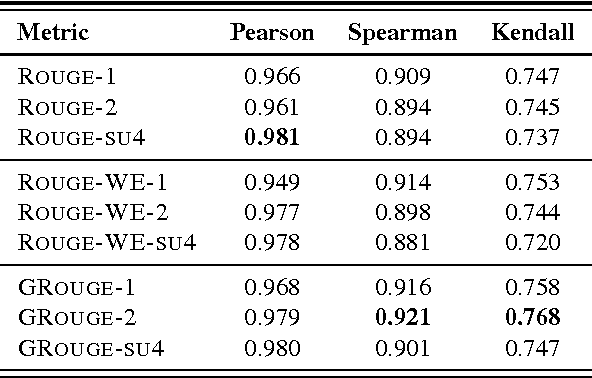
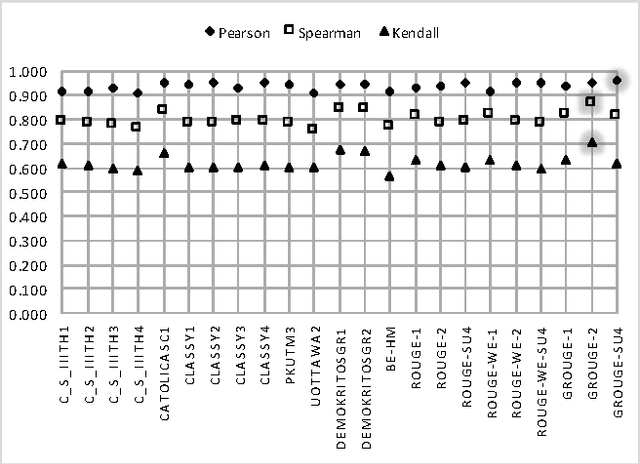
ROUGE is one of the first and most widely used evaluation metrics for text summarization. However, its assessment merely relies on surface similarities between peer and model summaries. Consequently, ROUGE is unable to fairly evaluate abstractive summaries including lexical variations and paraphrasing. Exploring the effectiveness of lexical resource-based models to address this issue, we adopt a graph-based algorithm into ROUGE to capture the semantic similarities between peer and model summaries. Our semantically motivated approach computes ROUGE scores based on both lexical and semantic similarities. Experiment results over TAC AESOP datasets indicate that exploiting the lexico-semantic similarity of the words used in summaries would significantly help ROUGE correlate better with human judgments.