 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDensely Supervised Grasp Detector (DSGD)
Paper and Code
Oct 01, 2018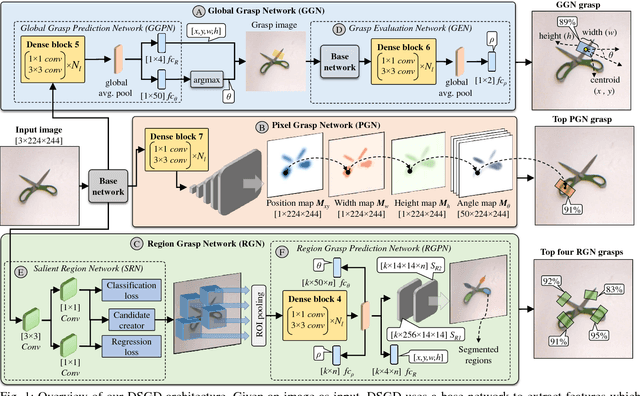
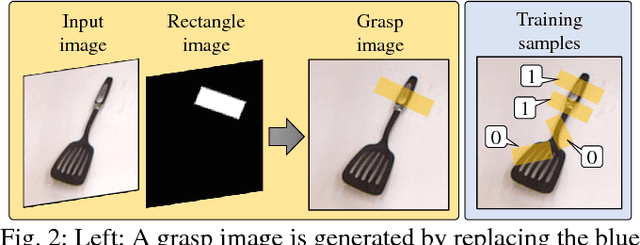
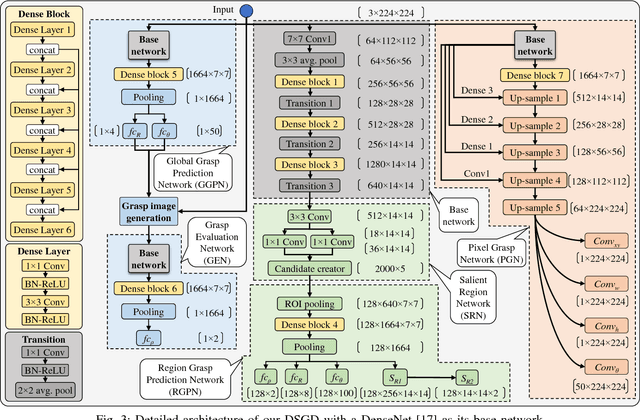

This paper presents Densely Supervised Grasp Detector (DSGD), a deep learning framework which combines CNN structures with layer-wise feature fusion and produces grasps and their confidence scores at different levels of the image hierarchy (i.e., global-, region-, and pixel-levels). Specifically, at the global-level, DSGD uses the entire image information to predict a grasp and its confidence score. At the region-level, DSGD uses a region proposal network to identify salient regions in the image and predicts a grasp for each salient region. At the pixel-level, DSGD uses a fully convolutional network and predicts a grasp and its confidence at every pixel. The grasp with the highest confidence score is selected as the output of DSGD. This selection from hierarchically generated grasp candidates overcomes limitations of the individual models. DSGD outperforms state-of-the-art methods on the Cornell grasp dataset in terms of grasp accuracy. Evaluation on a multi-object dataset and real-world robotic grasping experiments show that DSGD produces highly stable grasps on a set of unseen objects in new environments. It achieves 96% grasp detection accuracy and 90% robotic grasping success rate with real-time inference speed.