 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssessing AI vs Human-Authored Spear Phishing SMS Attacks: An Empirical Study Using the TRAPD Method
Jun 18, 2024



This paper explores the rising concern of utilizing Large Language Models (LLMs) in spear phishing message generation, and their performance compared to human-authored counterparts. Our pilot study compares the effectiveness of smishing (SMS phishing) messages created by GPT-4 and human authors, which have been personalized to willing targets. The targets assessed the messages in a modified ranked-order experiment using a novel methodology we call TRAPD (Threshold Ranking Approach for Personalized Deception). Specifically, targets provide personal information (job title and location, hobby, item purchased online), spear smishing messages are created using this information by humans and GPT-4, targets are invited back to rank-order 12 messages from most to least convincing (and identify which they would click on), and then asked questions about why they ranked messages the way they did. They also guess which messages are created by an LLM and their reasoning. Results from 25 targets show that LLM-generated messages are most often perceived as more convincing than those authored by humans, with messages related to jobs being the most convincing. We characterize different criteria used when assessing the authenticity of messages including word choice, style, and personal relevance. Results also show that targets were unable to identify whether the messages was AI-generated or human-authored and struggled to identify criteria to use in order to make this distinction. This study aims to highlight the urgent need for further research and improved countermeasures against personalized AI-enabled social engineering attacks.
Learning Physical Models that Can Respect Conservation Laws
Feb 21, 2023Recent work in scientific machine learning (SciML) has focused on incorporating partial differential equation (PDE) information into the learning process. Much of this work has focused on relatively ``easy'' PDE operators (e.g., elliptic and parabolic), with less emphasis on relatively ``hard'' PDE operators (e.g., hyperbolic). Within numerical PDEs, the latter problem class requires control of a type of volume element or conservation constraint, which is known to be challenging. Delivering on the promise of SciML requires seamlessly incorporating both types of problems into the learning process. To address this issue, we propose ProbConserv, a framework for incorporating conservation constraints into a generic SciML architecture. To do so, ProbConserv combines the integral form of a conservation law with a Bayesian update. We provide a detailed analysis of ProbConserv on learning with the Generalized Porous Medium Equation (GPME), a widely-applicable parameterized family of PDEs that illustrates the qualitative properties of both easier and harder PDEs. ProbConserv is effective for easy GPME variants, performing well with state-of-the-art competitors; and for harder GPME variants it outperforms other approaches that do not guarantee volume conservation. ProbConserv seamlessly enforces physical conservation constraints, maintains probabilistic uncertainty quantification (UQ), and deals well with shocks and heteroscedasticities. In each case, it achieves superior predictive performance on downstream tasks.
Scalable Bayesian Inference for Detection and Deblending in Astronomical Images
Jul 12, 2022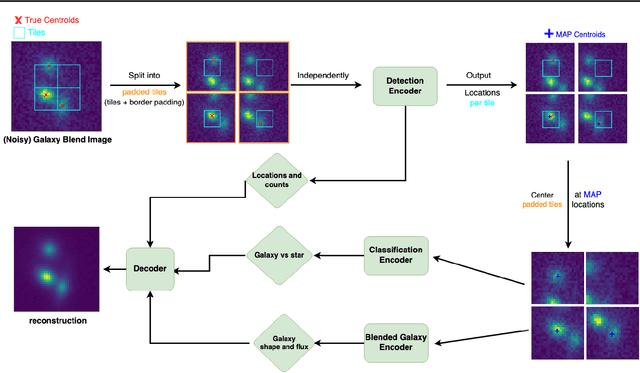
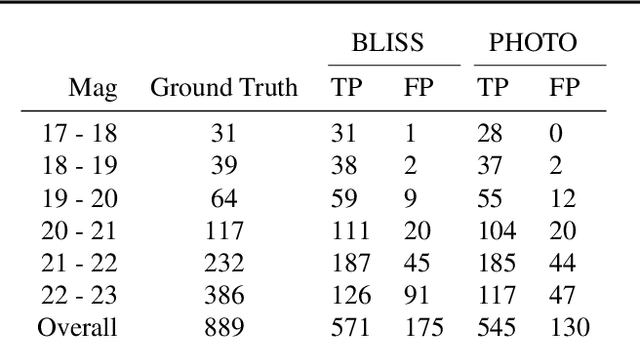

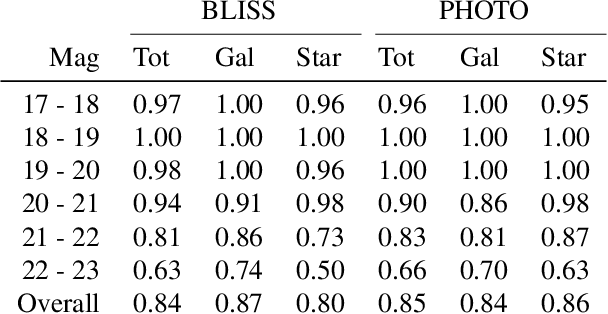
We present a new probabilistic method for detecting, deblending, and cataloging astronomical sources called the Bayesian Light Source Separator (BLISS). BLISS is based on deep generative models, which embed neural networks within a Bayesian model. For posterior inference, BLISS uses a new form of variational inference known as Forward Amortized Variational Inference. The BLISS inference routine is fast, requiring a single forward pass of the encoder networks on a GPU once the encoder networks are trained. BLISS can perform fully Bayesian inference on megapixel images in seconds, and produces highly accurate catalogs. BLISS is highly extensible, and has the potential to directly answer downstream scientific questions in addition to producing probabilistic catalogs.
Normalizing Flows for Knockoff-free Controlled Feature Selection
Jun 03, 2021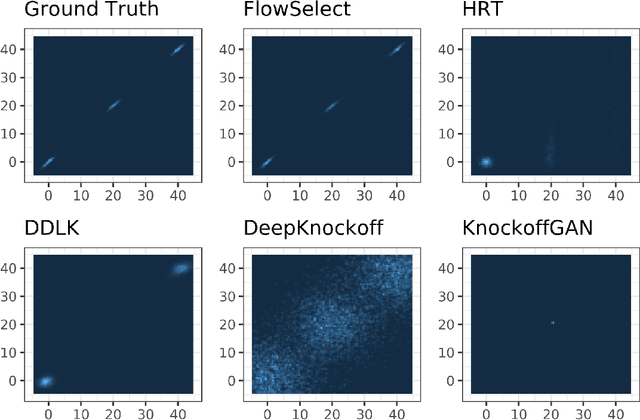


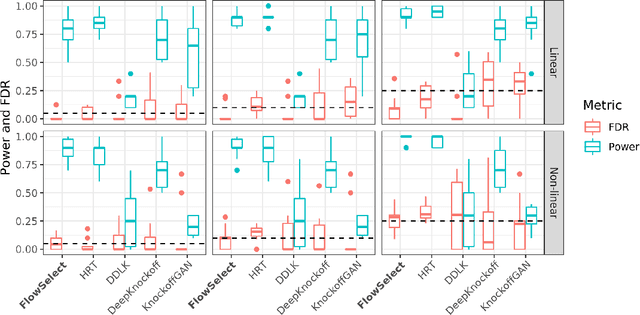
The goal of controlled feature selection is to discover the features a response depends on while limiting the proportion of false discoveries to a predefined level. Recently, multiple methods have been proposed that use deep learning to generate knockoffs for controlled feature selection through the Model-X knockoff framework. We demonstrate, however, that these methods often fail to control the false discovery rate (FDR). There are two reasons for this shortcoming. First, these methods often learn inaccurate models of features. Second, the "swap" property, which is required for knockoffs to be valid, is often not well enforced. We propose a new procedure called FlowSelect that remedies both of these problems. To more accurately model the features, FlowSelect uses normalizing flows, the state-of-the-art method for density estimation. To circumvent the need to enforce the swap property, FlowSelect uses a novel MCMC-based procedure to directly compute p-values for each feature. Asymptotically, FlowSelect controls the FDR exactly. Empirically, FlowSelect controls the FDR well on both synthetic and semi-synthetic benchmarks, whereas competing knockoff-based approaches fail to do so. FlowSelect also demonstrates greater power on these benchmarks. Additionally, using data from a genome-wide association study of soybeans, FlowSelect correctly infers the genetic variants associated with specific soybean traits.