 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNormalizing Flows for Knockoff-free Controlled Feature Selection
Paper and Code
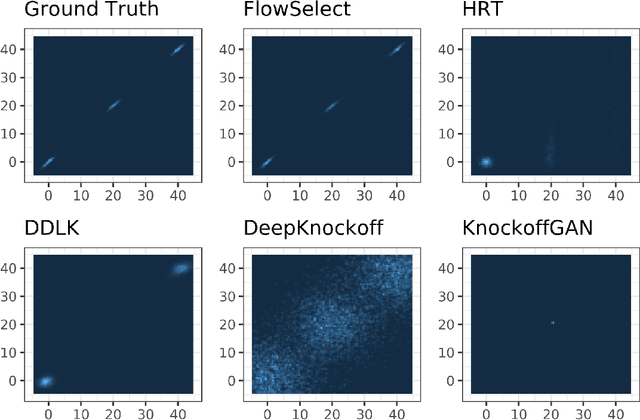


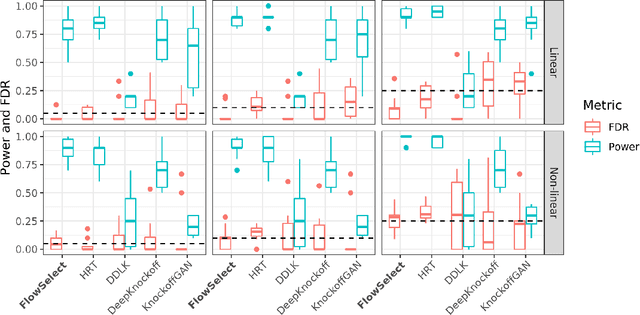
The goal of controlled feature selection is to discover the features a response depends on while limiting the proportion of false discoveries to a predefined level. Recently, multiple methods have been proposed that use deep learning to generate knockoffs for controlled feature selection through the Model-X knockoff framework. We demonstrate, however, that these methods often fail to control the false discovery rate (FDR). There are two reasons for this shortcoming. First, these methods often learn inaccurate models of features. Second, the "swap" property, which is required for knockoffs to be valid, is often not well enforced. We propose a new procedure called FlowSelect that remedies both of these problems. To more accurately model the features, FlowSelect uses normalizing flows, the state-of-the-art method for density estimation. To circumvent the need to enforce the swap property, FlowSelect uses a novel MCMC-based procedure to directly compute p-values for each feature. Asymptotically, FlowSelect controls the FDR exactly. Empirically, FlowSelect controls the FDR well on both synthetic and semi-synthetic benchmarks, whereas competing knockoff-based approaches fail to do so. FlowSelect also demonstrates greater power on these benchmarks. Additionally, using data from a genome-wide association study of soybeans, FlowSelect correctly infers the genetic variants associated with specific soybean traits.