 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStatistical Inference for Coadded Astronomical Images
Nov 17, 2022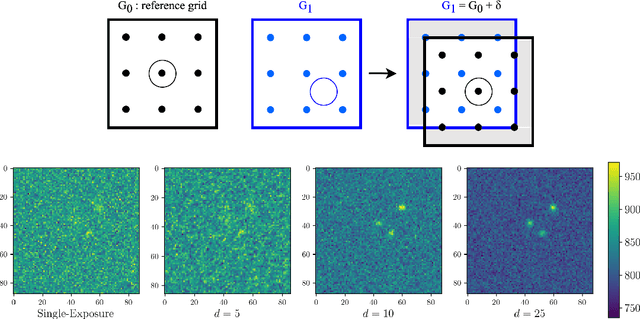
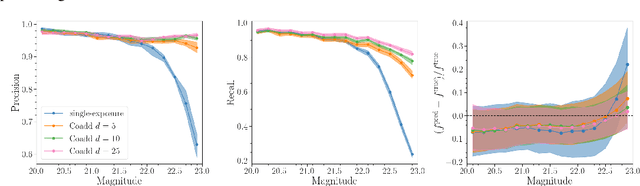
Coadded astronomical images are created by stacking multiple single-exposure images. Because coadded images are smaller in terms of data size than the single-exposure images they summarize, loading and processing them is less computationally expensive. However, image coaddition introduces additional dependence among pixels, which complicates principled statistical analysis of them. We present a principled Bayesian approach for performing light source parameter inference with coadded astronomical images. Our method implicitly marginalizes over the single-exposure pixel intensities that contribute to the coadded images, giving it the computational efficiency necessary to scale to next-generation astronomical surveys. As a proof of concept, we show that our method for estimating the locations and fluxes of stars using simulated coadds outperforms a method trained on single-exposure images.
Maximum Relevance and Minimum Redundancy Feature Selection Methods for a Marketing Machine Learning Platform
Aug 15, 2019

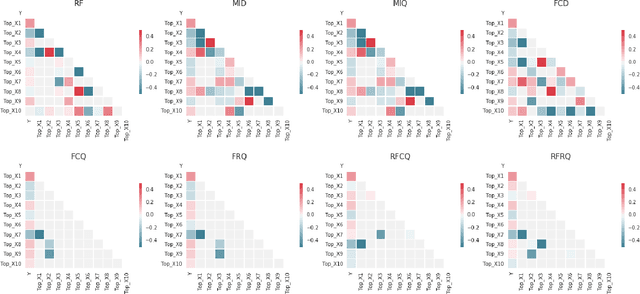

In machine learning applications for online product offerings and marketing strategies, there are often hundreds or thousands of features available to build such models. Feature selection is one essential method in such applications for multiple objectives: improving the prediction accuracy by eliminating irrelevant features, accelerating the model training and prediction speed, reducing the monitoring and maintenance workload for feature data pipeline, and providing better model interpretation and diagnosis capability. However, selecting an optimal feature subset from a large feature space is considered as an NP-complete problem. The mRMR (Minimum Redundancy and Maximum Relevance) feature selection framework solves this problem by selecting the relevant features while controlling for the redundancy within the selected features. This paper describes the approach to extend, evaluate, and implement the mRMR feature selection methods for classification problem in a marketing machine learning platform at Uber that automates creation and deployment of targeting and personalization models at scale. This study first extends the existing mRMR methods by introducing a non-linear feature redundancy measure and a model-based feature relevance measure. Then an extensive empirical evaluation is performed for eight different feature selection methods, using one synthetic dataset and three real-world marketing datasets at Uber to cover different use cases. Based on the empirical results, the selected mRMR method is implemented in production for the marketing machine learning platform. A description of the production implementation is provided and an online experiment deployed through the platform is discussed.