 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWound Tissue Segmentation in Diabetic Foot Ulcer Images Using Deep Learning: A Pilot Study
Jun 23, 2024Identifying individual tissues, so-called tissue segmentation, in diabetic foot ulcer (DFU) images is a challenging task and little work has been published, largely due to the limited availability of a clinical image dataset. To address this gap, we have created a DFUTissue dataset for the research community to evaluate wound tissue segmentation algorithms. The dataset contains 110 images with tissues labeled by wound experts and 600 unlabeled images. Additionally, we conducted a pilot study on segmenting wound characteristics including fibrin, granulation, and callus using deep learning. Due to the limited amount of annotated data, our framework consists of both supervised learning (SL) and semi-supervised learning (SSL) phases. In the SL phase, we propose a hybrid model featuring a Mix Transformer (MiT-b3) in the encoder and a CNN in the decoder, enhanced by the integration of a parallel spatial and channel squeeze-and-excitation (P-scSE) module known for its efficacy in improving boundary accuracy. The SSL phase employs a pseudo-labeling-based approach, iteratively identifying and incorporating valuable unlabeled images to enhance overall segmentation performance. Comparative evaluations with state-of-the-art methods are conducted for both SL and SSL phases. The SL achieves a Dice Similarity Coefficient (DSC) of 84.89%, which has been improved to 87.64% in the SSL phase. Furthermore, the results are benchmarked against two widely used SSL approaches: Generative Adversarial Networks and Cross-Consistency Training. Additionally, our hybrid model outperforms the state-of-the-art methods with a 92.99% DSC in performing binary segmentation of DFU wound areas when tested on the Chronic Wound dataset. Codes and data are available at https://github.com/uwm-bigdata/DFUTissueSegNet.
A Deep Learning Approach to Teeth Segmentation and Orientation from Panoramic X-rays
Oct 26, 2023Accurate teeth segmentation and orientation are fundamental in modern oral healthcare, enabling precise diagnosis, treatment planning, and dental implant design. In this study, we present a comprehensive approach to teeth segmentation and orientation from panoramic X-ray images, leveraging deep learning techniques. We build our model based on FUSegNet, a popular model originally developed for wound segmentation, and introduce modifications by incorporating grid-based attention gates into the skip connections. We introduce oriented bounding box (OBB) generation through principal component analysis (PCA) for precise tooth orientation estimation. Evaluating our approach on the publicly available DNS dataset, comprising 543 panoramic X-ray images, we achieve the highest Intersection-over-Union (IoU) score of 82.43% and Dice Similarity Coefficient (DSC) score of 90.37% among compared models in teeth instance segmentation. In OBB analysis, we obtain the Rotated IoU (RIoU) score of 82.82%. We also conduct detailed analyses of individual tooth labels and categorical performance, shedding light on strengths and weaknesses. The proposed model's accuracy and versatility offer promising prospects for improving dental diagnoses, treatment planning, and personalized healthcare in the oral domain. Our generated OBB coordinates and codes are available at https://github.com/mrinal054/Instance_teeth_segmentation.
Integrated Image and Location Analysis for Wound Classification: A Deep Learning Approach
Aug 24, 2023The global burden of acute and chronic wounds presents a compelling case for enhancing wound classification methods, a vital step in diagnosing and determining optimal treatments. Recognizing this need, we introduce an innovative multi-modal network based on a deep convolutional neural network for categorizing wounds into four categories: diabetic, pressure, surgical, and venous ulcers. Our multi-modal network uses wound images and their corresponding body locations for more precise classification. A unique aspect of our methodology is incorporating a body map system that facilitates accurate wound location tagging, improving upon traditional wound image classification techniques. A distinctive feature of our approach is the integration of models such as VGG16, ResNet152, and EfficientNet within a novel architecture. This architecture includes elements like spatial and channel-wise Squeeze-and-Excitation modules, Axial Attention, and an Adaptive Gated Multi-Layer Perceptron, providing a robust foundation for classification. Our multi-modal network was trained and evaluated on two distinct datasets comprising relevant images and corresponding location information. Notably, our proposed network outperformed traditional methods, reaching an accuracy range of 74.79% to 100% for Region of Interest (ROI) without location classifications, 73.98% to 100% for ROI with location classifications, and 78.10% to 100% for whole image classifications. This marks a significant enhancement over previously reported performance metrics in the literature. Our results indicate the potential of our multi-modal network as an effective decision-support tool for wound image classification, paving the way for its application in various clinical contexts.
FUSegNet: A Deep Convolutional Neural Network for Foot Ulcer Segmentation
May 04, 2023



This paper presents FUSegNet, a new model for foot ulcer segmentation in diabetes patients, which uses the pre-trained EfficientNet-b7 as a backbone to address the issue of limited training samples. A modified spatial and channel squeeze-and-excitation (scSE) module called parallel scSE or P-scSE is proposed that combines additive and max-out scSE. A new arrangement is introduced for the module by fusing it in the middle of each decoder stage. As the top decoder stage carries a limited number of feature maps, max-out scSE is bypassed there to form a shorted P-scSE. A set of augmentations, comprising geometric, morphological, and intensity-based augmentations, is applied before feeding the data into the network. The proposed model is first evaluated on a publicly available chronic wound dataset where it achieves a data-based dice score of 92.70%, which is the highest score among the reported approaches. The model outperforms other scSE-based UNet models in terms of Pratt's figure of merits (PFOM) scores in most categories, which evaluates the accuracy of edge localization. The model is then tested in the MICCAI 2021 FUSeg challenge, where a variation of FUSegNet called x-FUSegNet is submitted. The x-FUSegNet model, which takes the average of outputs obtained by FUSegNet using 5-fold cross-validation, achieves a dice score of 89.23%, placing it at the top of the FUSeg Challenge leaderboard. The source code for the model is available on https://github.com/mrinal054/FUSegNet.
S-R2F2U-Net: A single-stage model for teeth segmentation
Apr 06, 2022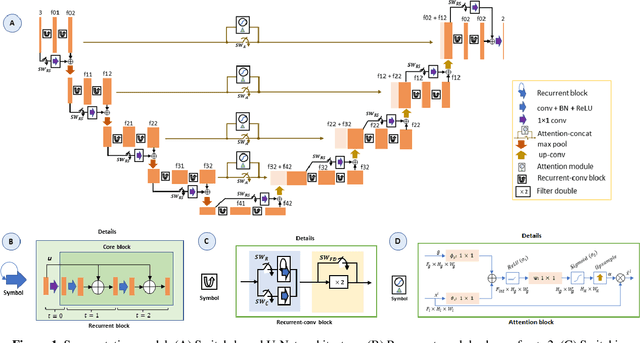
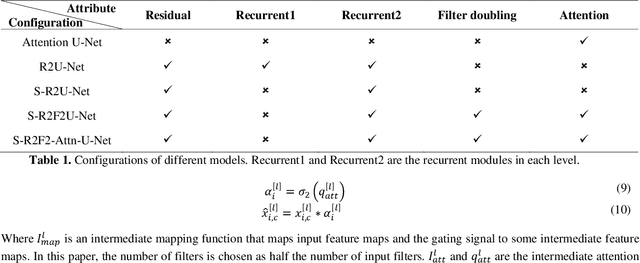
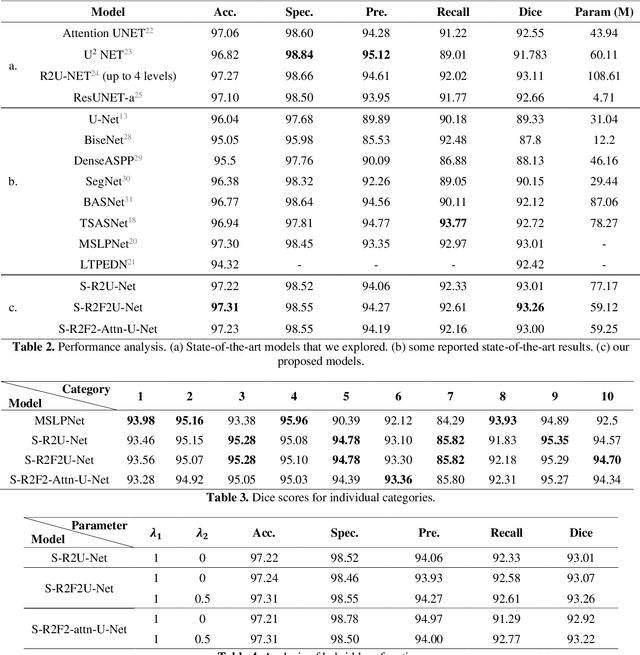

Precision tooth segmentation is crucial in the oral sector because it provides location information for orthodontic therapy, clinical diagnosis, and surgical treatments. In this paper, we investigate residual, recurrent, and attention networks to segment teeth from panoramic dental images. Based on our findings, we suggest three single-stage models: Single Recurrent R2U-Net (S-R2U-Net), Single Recurrent Filter Double R2U-Net (S-R2F2U-Net), and Single Recurrent Attention Enabled Filter Double (S-R2F2-Attn-U-Net). Particularly, S-R2F2U-Net outperforms state-of-the-art models in terms of accuracy and dice score. A hybrid loss function combining the cross-entropy loss and dice loss is used to train the model. In addition, it reduces around 45% of model parameters compared to the R2U-Net model. Models are trained and evaluated on a benchmark dataset containing 1500 dental panoramic X-ray images. S-R2F2U-Net achieves 97.31% of accuracy and 93.26% of dice score, showing superiority over the state-of-the-art methods. Codes are available at https://github.com/mrinal054/teethSeg_sr2f2u-net.git.
Automatic tracing of mandibular canal pathways using deep learning
Nov 30, 2021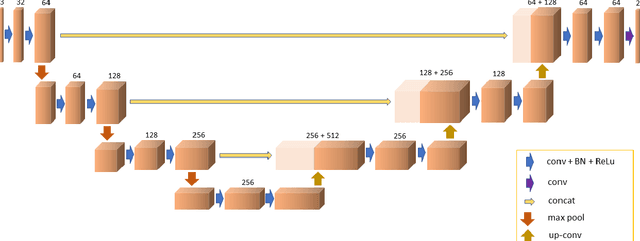
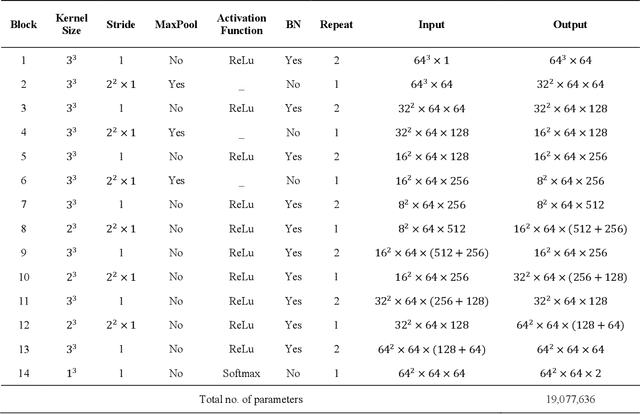
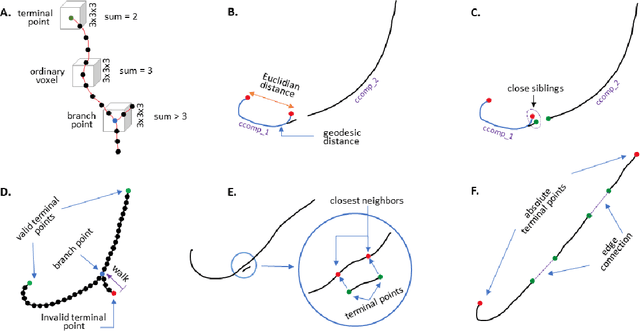
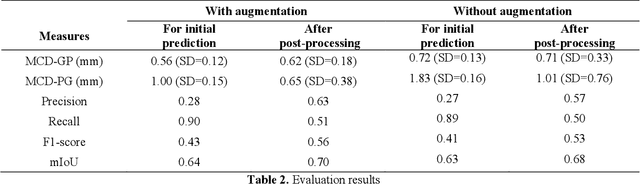
There is an increasing demand in medical industries to have automated systems for detection and localization which are manually inefficient otherwise. In dentistry, it bears great interest to trace the pathway of mandibular canals accurately. Proper localization of the position of the mandibular canals, which surrounds the inferior alveolar nerve (IAN), reduces the risk of damaging it during dental implantology. Manual detection of canal paths is not an efficient way in terms of time and labor. Here, we propose a deep learning-based framework to detect mandibular canals from CBCT data. It is a 3-stage process fully automatic end-to-end. Ground truths are generated in the preprocessing stage. Instead of using commonly used fixed diameter tubular-shaped ground truth, we generate centerlines of the mandibular canals and used them as ground truths in the training process. A 3D U-Net architecture is used for model training. An efficient post-processing stage is developed to rectify the initial prediction. The precision, recall, F1-score, and IoU are measured to analyze the voxel-level segmentation performance. However, to analyze the distance-based measurements, mean curve distance (MCD) both from ground truth to prediction and prediction to ground truth is calculated. Extensive experiments are conducted to demonstrate the effectiveness of the model.
Fully Automatic Wound Segmentation with Deep Convolutional Neural Networks
Oct 12, 2020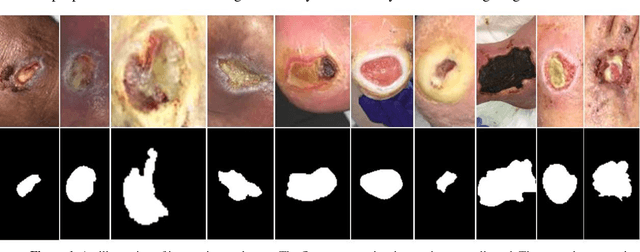
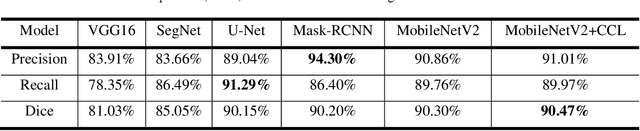
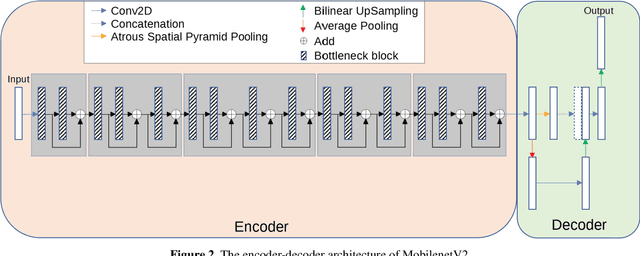

Acute and chronic wounds have varying etiologies and are an economic burden to healthcare systems around the world. The advanced wound care market is expected to exceed $22 billion by 2024. Wound care professionals rely heavily on images and image documentation for proper diagnosis and treatment. Unfortunately lack of expertise can lead to improper diagnosis of wound etiology and inaccurate wound management and documentation. Fully automatic segmentation of wound areas in natural images is an important part of the diagnosis and care protocol since it is crucial to measure the area of the wound and provide quantitative parameters in the treatment. Various deep learning models have gained success in image analysis including semantic segmentation. Particularly, MobileNetV2 stands out among others due to its lightweight architecture and uncompromised performance. This manuscript proposes a novel convolutional framework based on MobileNetV2 and connected component labelling to segment wound regions from natural images. We build an annotated wound image dataset consisting of 1,109 foot ulcer images from 889 patients to train and test the deep learning models. We demonstrate the effectiveness and mobility of our method by conducting comprehensive experiments and analyses on various segmentation neural networks.