 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFully Automatic Wound Segmentation with Deep Convolutional Neural Networks
Oct 12, 2020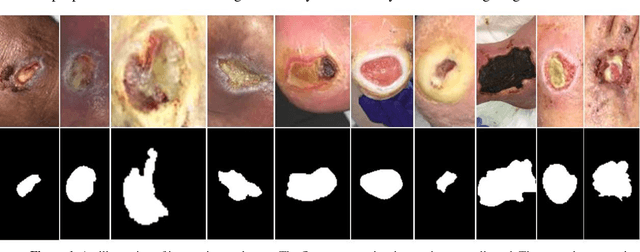
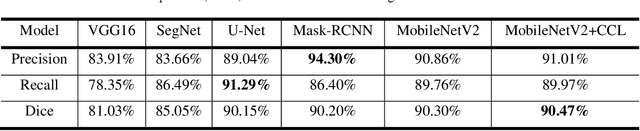
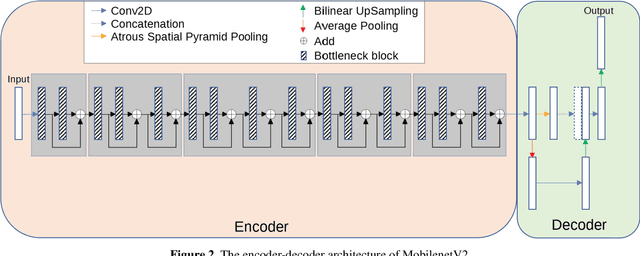

Acute and chronic wounds have varying etiologies and are an economic burden to healthcare systems around the world. The advanced wound care market is expected to exceed $22 billion by 2024. Wound care professionals rely heavily on images and image documentation for proper diagnosis and treatment. Unfortunately lack of expertise can lead to improper diagnosis of wound etiology and inaccurate wound management and documentation. Fully automatic segmentation of wound areas in natural images is an important part of the diagnosis and care protocol since it is crucial to measure the area of the wound and provide quantitative parameters in the treatment. Various deep learning models have gained success in image analysis including semantic segmentation. Particularly, MobileNetV2 stands out among others due to its lightweight architecture and uncompromised performance. This manuscript proposes a novel convolutional framework based on MobileNetV2 and connected component labelling to segment wound regions from natural images. We build an annotated wound image dataset consisting of 1,109 foot ulcer images from 889 patients to train and test the deep learning models. We demonstrate the effectiveness and mobility of our method by conducting comprehensive experiments and analyses on various segmentation neural networks.
Improving Yorùbá Diacritic Restoration
Mar 23, 2020
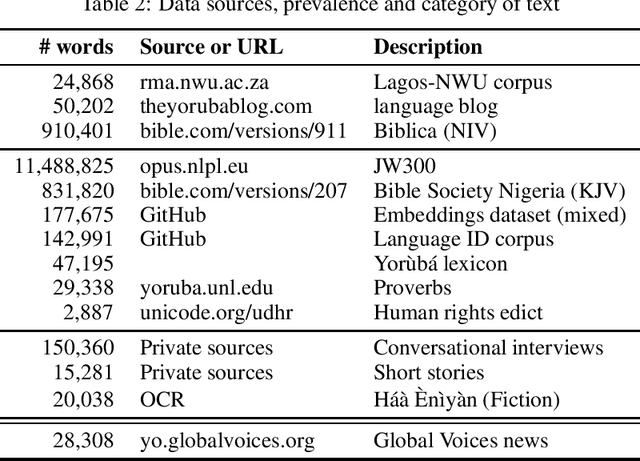
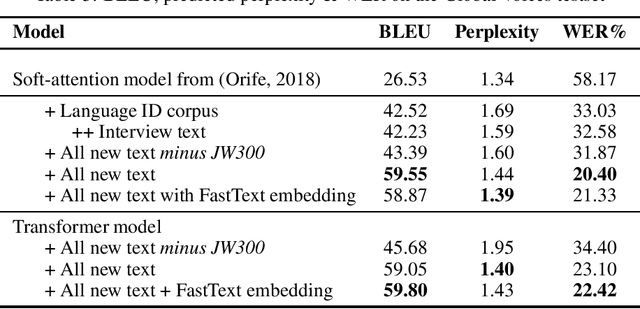
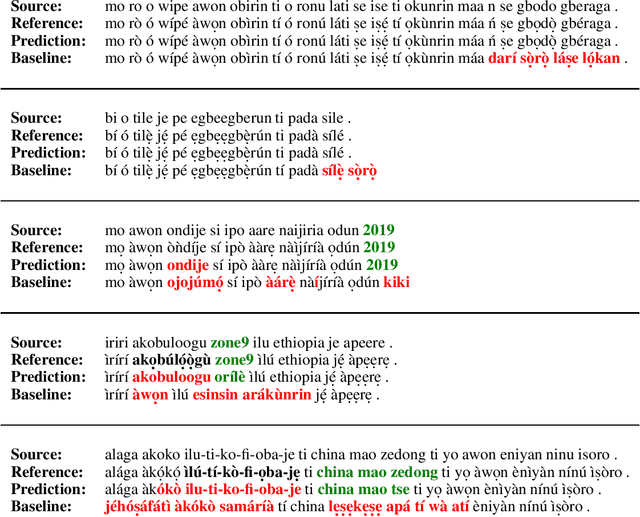
Yor\`ub\'a is a widely spoken West African language with a writing system rich in orthographic and tonal diacritics. They provide morphological information, are crucial for lexical disambiguation, pronunciation and are vital for any computational Speech or Natural Language Processing tasks. However diacritic marks are commonly excluded from electronic texts due to limited device and application support as well as general education on proper usage. We report on recent efforts at dataset cultivation. By aggregating and improving disparate texts from the web and various personal libraries, we were able to significantly grow our clean Yor\`ub\'a dataset from a majority Bibilical text corpora with three sources to millions of tokens from over a dozen sources. We evaluate updated diacritic restoration models on a new, general purpose, public-domain Yor\`ub\'a evaluation dataset of modern journalistic news text, selected to be multi-purpose and reflecting contemporary usage. All pre-trained models, datasets and source-code have been released as an open-source project to advance efforts on Yor\`ub\'a language technology.