 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDIS2: Disentanglement Meets Distillation with Classwise Attention for Robust Remote Sensing Segmentation under Missing Modalities
Jan 20, 2026The efficacy of multimodal learning in remote sensing (RS) is severely undermined by missing modalities. The challenge is exacerbated by the RS highly heterogeneous data and huge scale variation. Consequently, paradigms proven effective in other domains often fail when confronted with these unique data characteristics. Conventional disentanglement learning, which relies on significant feature overlap between modalities (modality-invariant), is insufficient for this heterogeneity. Similarly, knowledge distillation becomes an ill-posed mimicry task where a student fails to focus on the necessary compensatory knowledge, leaving the semantic gap unaddressed. Our work is therefore built upon three pillars uniquely designed for RS: (1) principled missing information compensation, (2) class-specific modality contribution, and (3) multi-resolution feature importance. We propose a novel method DIS2, a new paradigm shifting from modality-shared feature dependence and untargeted imitation to active, guided missing features compensation. Its core novelty lies in a reformulated synergy between disentanglement learning and knowledge distillation, termed DLKD. Compensatory features are explicitly captured which, when fused with the features of the available modality, approximate the ideal fused representation of the full-modality case. To address the class-specific challenge, our Classwise Feature Learning Module (CFLM) adaptively learn discriminative evidence for each target depending on signal availability. Both DLKD and CFLM are supported by a hierarchical hybrid fusion (HF) structure using features across resolutions to strengthen prediction. Extensive experiments validate that our proposed approach significantly outperforms state-of-the-art methods across benchmarks.
General-Purpose Multimodal Transformer meets Remote Sensing Semantic Segmentation
Jul 07, 2023

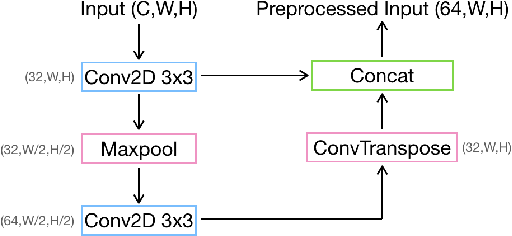
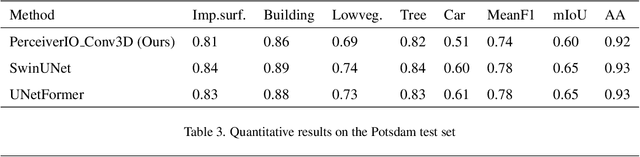
The advent of high-resolution multispectral/hyperspectral sensors, LiDAR DSM (Digital Surface Model) information and many others has provided us with an unprecedented wealth of data for Earth Observation. Multimodal AI seeks to exploit those complementary data sources, particularly for complex tasks like semantic segmentation. While specialized architectures have been developed, they are highly complicated via significant effort in model design, and require considerable re-engineering whenever a new modality emerges. Recent trends in general-purpose multimodal networks have shown great potential to achieve state-of-the-art performance across multiple multimodal tasks with one unified architecture. In this work, we investigate the performance of PerceiverIO, one in the general-purpose multimodal family, in the remote sensing semantic segmentation domain. Our experiments reveal that this ostensibly universal network struggles with object scale variation in remote sensing images and fails to detect the presence of cars from a top-down view. To address these issues, even with extreme class imbalance issues, we propose a spatial and volumetric learning component. Specifically, we design a UNet-inspired module that employs 3D convolution to encode vital local information and learn cross-modal features simultaneously, while reducing network computational burden via the cross-attention mechanism of PerceiverIO. The effectiveness of the proposed component is validated through extensive experiments comparing it with other methods such as 2D convolution, and dual local module (\ie the combination of Conv2D 1x1 and Conv2D 3x3 inspired by UNetFormer). The proposed method achieves competitive results with specialized architectures like UNetFormer and SwinUNet, showing its potential to minimize network architecture engineering with a minimal compromise on the performance.