 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemEval-2020 Task 7: Assessing Humor in Edited News Headlines
Aug 01, 2020


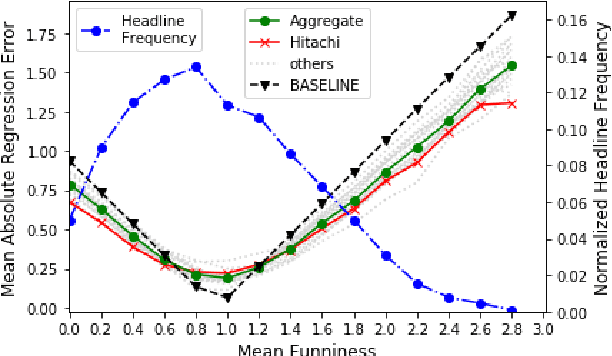
This paper describes the SemEval-2020 shared task "Assessing Humor in Edited News Headlines." The task's dataset contains news headlines in which short edits were applied to make them funny, and the funniness of these edited headlines was rated using crowdsourcing. This task includes two subtasks, the first of which is to estimate the funniness of headlines on a humor scale in the interval 0-3. The second subtask is to predict, for a pair of edited versions of the same original headline, which is the funnier version. To date, this task is the most popular shared computational humor task, attracting 48 teams for the first subtask and 31 teams for the second.
"Judge me by my size , do you?'' YodaLib: A Demographic-Aware Humor Generation Framework
May 31, 2020



The subjective nature of humor makes computerized humor generation a challenging task. We propose an automatic humor generation framework for filling the blanks in Mad Libs stories, while accounting for the demographic backgrounds of the desired audience. We collect a dataset consisting of such stories, which are filled in and judged by carefully selected workers on Amazon Mechanical Turk. We build upon the BERT platform to predict location-biased word fillings in incomplete sentences, and we fine tune BERT to classify location-specific humor in a sentence. We leverage these components to produce YodaLib, a fully-automated Mad Libs style humor generation framework, which selects and ranks appropriate candidate words and sentences in order to generate a coherent and funny story tailored to certain demographics. Our experimental results indicate that YodaLib outperforms a previous semi-automated approach proposed for this task, while also surpassing human annotators in both qualitative and quantitative analyses.
Stimulating Creativity with FunLines: A Case Study of Humor Generation in Headlines
Feb 05, 2020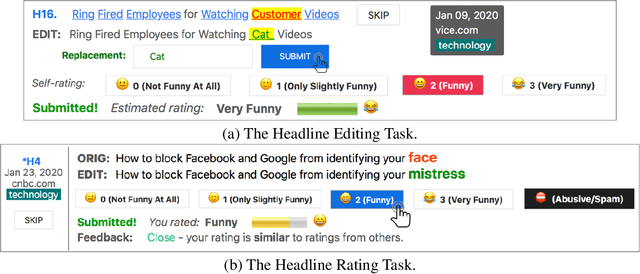


Building datasets of creative text, such as humor, is quite challenging. We introduce FunLines, a competitive game where players edit news headlines to make them funny, and where they rate the funniness of headlines edited by others. FunLines makes the humor generation process fun, interactive, collaborative, rewarding and educational, keeping players engaged and providing humor data at a very low cost compared to traditional crowdsourcing approaches. FunLines offers useful performance feedback, assisting players in getting better over time at generating and assessing humor, as our analysis shows. This helps to further increase the quality of the generated dataset. We show the effectiveness of this data by training humor classification models that outperform a previous benchmark, and we release this dataset to the public.
"President Vows to Cut <Taxes> Hair": Dataset and Analysis of Creative Text Editing for Humorous Headlines
Jun 01, 2019
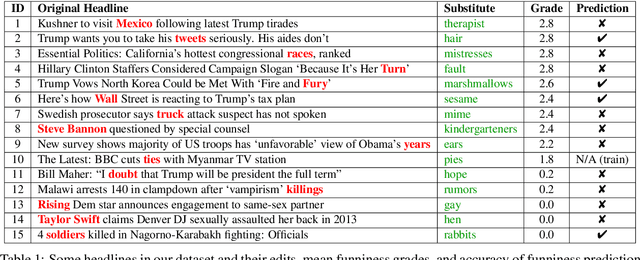
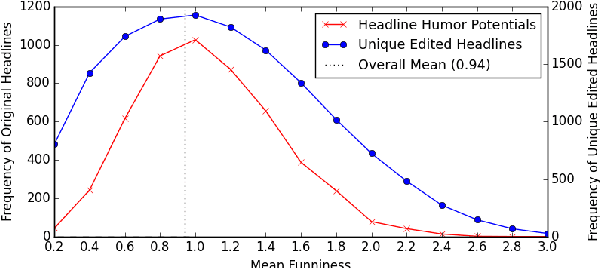
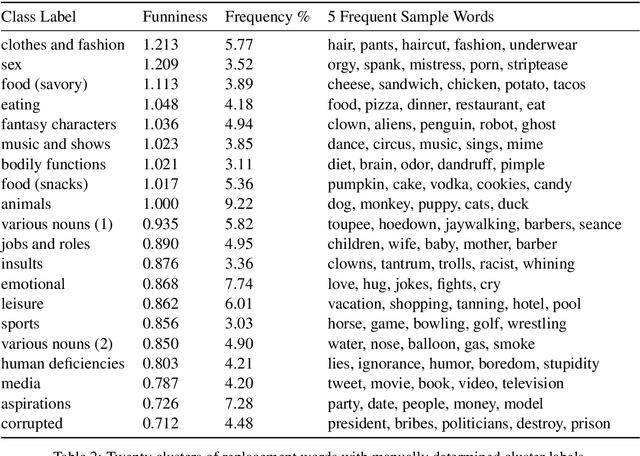
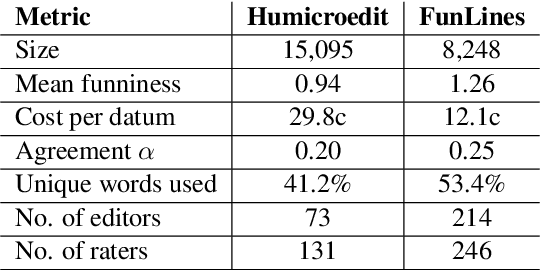
We introduce, release, and analyze a new dataset, called Humicroedit, for research in computational humor. Our publicly available data consists of regular English news headlines paired with versions of the same headlines that contain simple replacement edits designed to make them funny. We carefully curated crowdsourced editors to create funny headlines and judges to score a to a total of 15,095 edited headlines, with five judges per headline. The simple edits, usually just a single word replacement, mean we can apply straightforward analysis techniques to determine what makes our edited headlines humorous. We show how the data support classic theories of humor, such as incongruity, superiority, and setup/punchline. Finally, we develop baseline classifiers that can predict whether or not an edited headline is funny, which is a first step toward automatically generating humorous headlines as an approach to creating topical humor.
Inferring Fine-grained Details on User Activities and Home Location from Social Media: Detecting Drinking-While-Tweeting Patterns in Communities
Mar 10, 2016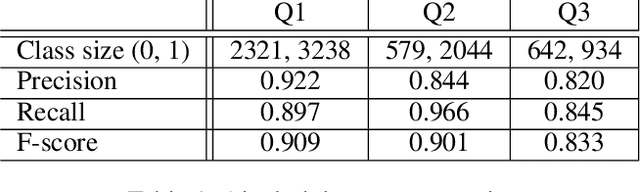
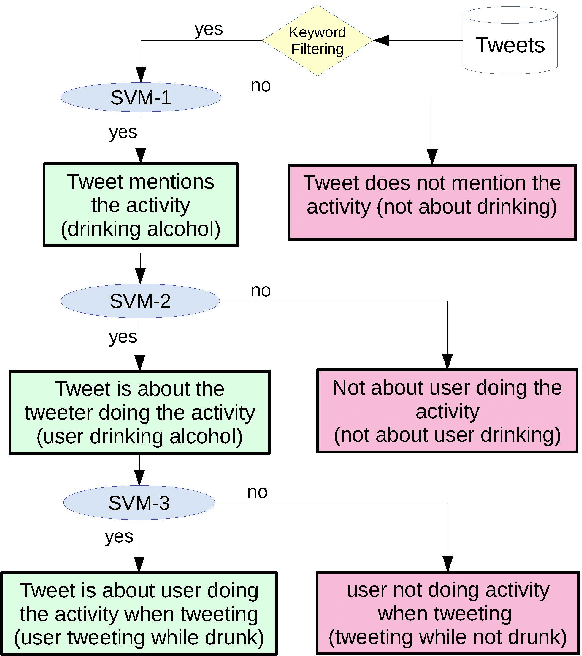
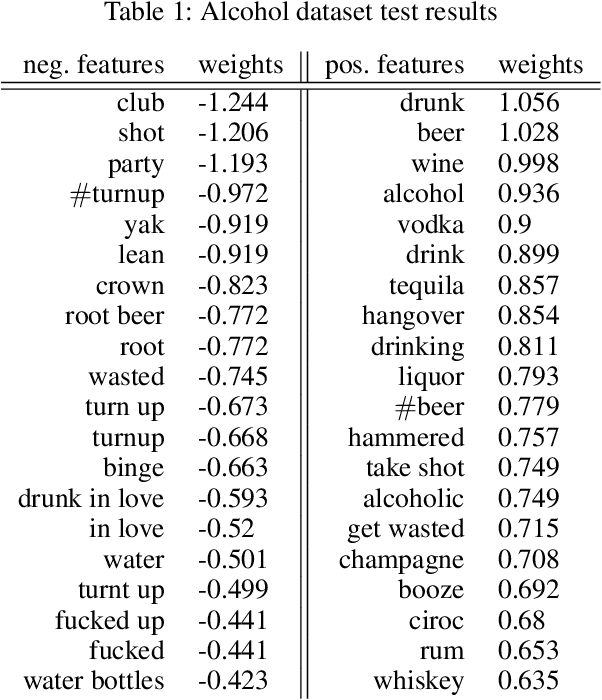
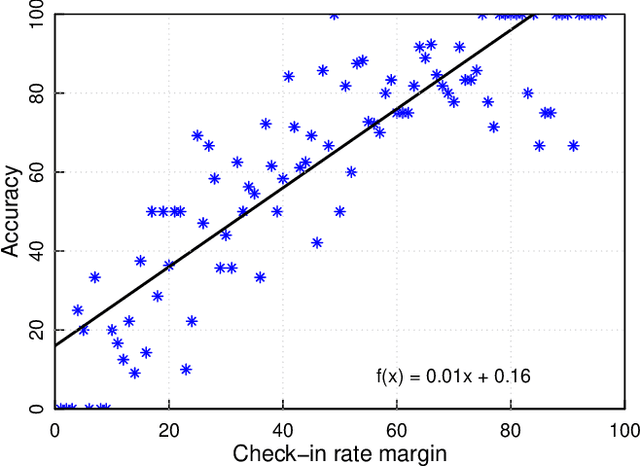
Nearly all previous work on geo-locating latent states and activities from social media confounds general discussions about activities, self-reports of users participating in those activities at times in the past or future, and self-reports made at the immediate time and place the activity occurs. Activities, such as alcohol consumption, may occur at different places and types of places, and it is important not only to detect the local regions where these activities occur, but also to analyze the degree of participation in them by local residents. In this paper, we develop new machine learning based methods for fine-grained localization of activities and home locations from Twitter data. We apply these methods to discover and compare alcohol consumption patterns in a large urban area, New York City, and a more suburban and rural area, Monroe County. We find positive correlations between the rate of alcohol consumption reported among a community's Twitter users and the density of alcohol outlets, demonstrating that the degree of correlation varies significantly between urban and suburban areas. While our experiments are focused on alcohol use, our methods for locating homes and distinguishing temporally-specific self-reports are applicable to a broad range of behaviors and latent states.