 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStylistic Retrieval-based Dialogue System with Unparallel Training Data
Sep 12, 2021

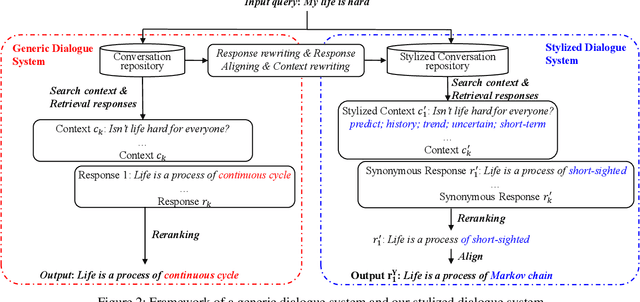
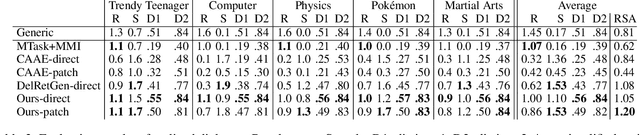
The ability of a dialog system to express consistent language style during conversations has a direct, positive impact on its usability and on user satisfaction. Although previous studies have demonstrated that style transfer is feasible with a large amount of parallel data, it is often impossible to collect such data for different styles. In this paper, instead of manually constructing conversation data with a certain style, we propose a flexible framework that adapts a generic retrieval-based dialogue system to mimic the language style of a specified persona without any parallel data. Our approach is based on automatic generation of stylized data by learning the usage of jargon, and then rewriting the generic conversations to a stylized one by incorporating the jargon. In experiments we implemented dialogue systems with five distinct language styles, and the result shows our framework significantly outperforms baselines in terms of the average score of responses' relevance and style degree, and content diversity. A/B testing on a commercial chatbot shows that users are more satisfied with our system. This study demonstrates the feasibility of building stylistic dialogue systems by simple data augmentation.
"Love is as Complex as Math": Metaphor Generation System for Social Chatbot
Jan 03, 2020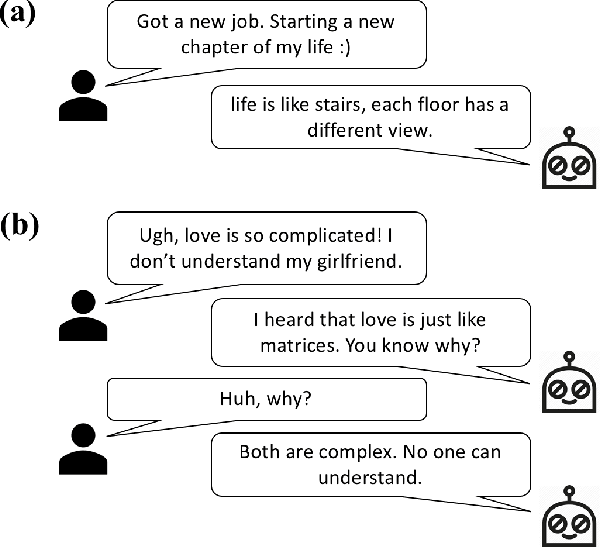
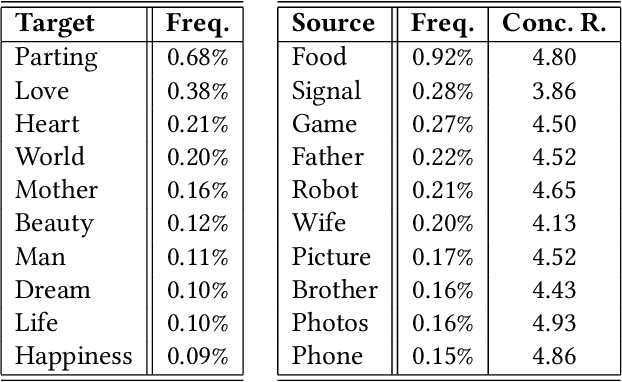
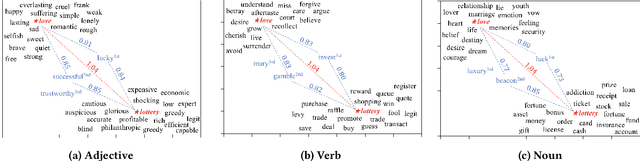
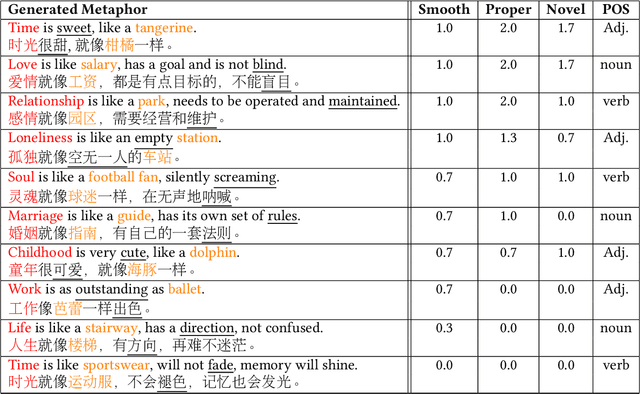
As the wide adoption of intelligent chatbot in human daily life, user demands for such systems evolve from basic task-solving conversations to more casual and friend-like communication. To meet the user needs and build emotional bond with users, it is essential for social chatbots to incorporate more human-like and advanced linguistic features. In this paper, we investigate the usage of a commonly used rhetorical device by human -- metaphor for social chatbot. Our work first designs a metaphor generation framework, which generates topic-aware and novel figurative sentences. By embedding the framework into a chatbot system, we then enables the chatbot to communicate with users using figurative language. Human annotators validate the novelty and properness of the generated metaphors. More importantly, we evaluate the effects of employing metaphors in human-chatbot conversations. Experiments indicate that our system effectively arouses user interests in communicating with our chatbot, resulting in significantly longer human-chatbot conversations.
A World of Difference: Divergent Word Interpretations among People
Mar 28, 2017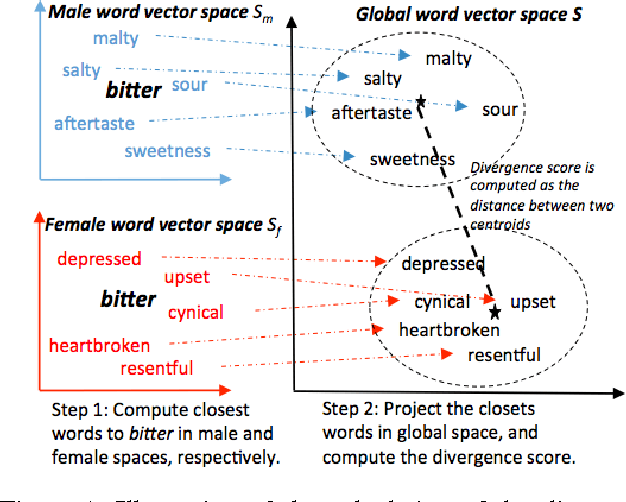
Divergent word usages reflect differences among people. In this paper, we present a novel angle for studying word usage divergence -- word interpretations. We propose an approach that quantifies semantic differences in interpretations among different groups of people. The effectiveness of our approach is validated by quantitative evaluations. Experiment results indicate that divergences in word interpretations exist. We further apply the approach to two well studied types of differences between people -- gender and region. The detected words with divergent interpretations reveal the unique features of specific groups of people. For gender, we discover that certain different interests, social attitudes, and characters between males and females are reflected in their divergent interpretations of many words. For region, we find that specific interpretations of certain words reveal the geographical and cultural features of different regions.
Spice up Your Chat: The Intentions and Sentiment Effects of Using Emoji
Mar 08, 2017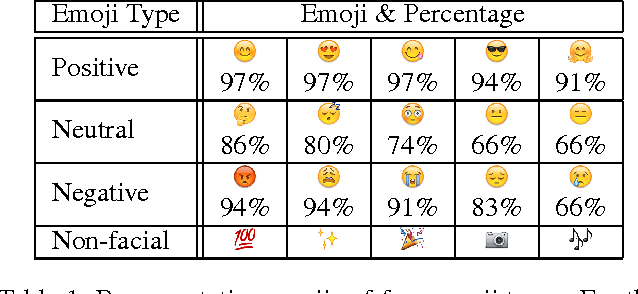



Emojis, as a new way of conveying nonverbal cues, are widely adopted in computer-mediated communications. In this paper, first from a message sender perspective, we focus on people's motives in using four types of emojis -- positive, neutral, negative, and non-facial. We compare the willingness levels of using these emoji types for seven typical intentions that people usually apply nonverbal cues for in communication. The results of extensive statistical hypothesis tests not only report the popularities of the intentions, but also uncover the subtle differences between emoji types in terms of intended uses. Second, from a perspective of message recipients, we further study the sentiment effects of emojis, as well as their duplications, on verbal messages. Different from previous studies in emoji sentiment, we study the sentiments of emojis and their contexts as a whole. The experiment results indicate that the powers of conveying sentiment are different between four emoji types, and the sentiment effects of emojis vary in the contexts of different valences.
What the Language You Tweet Says About Your Occupation
Jan 22, 2017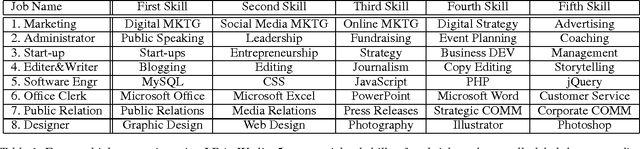
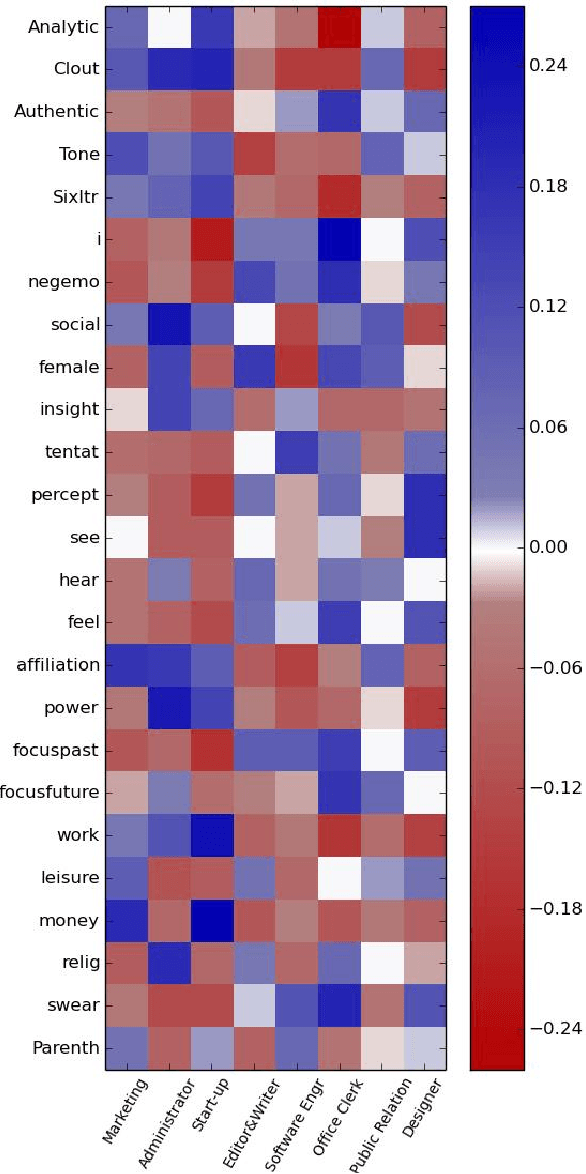

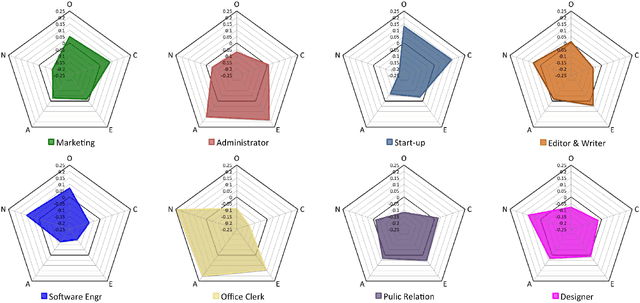
Many aspects of people's lives are proven to be deeply connected to their jobs. In this paper, we first investigate the distinct characteristics of major occupation categories based on tweets. From multiple social media platforms, we gather several types of user information. From users' LinkedIn webpages, we learn their proficiencies. To overcome the ambiguity of self-reported information, a soft clustering approach is applied to extract occupations from crowd-sourced data. Eight job categories are extracted, including Marketing, Administrator, Start-up, Editor, Software Engineer, Public Relation, Office Clerk, and Designer. Meanwhile, users' posts on Twitter provide cues for understanding their linguistic styles, interests, and personalities. Our results suggest that people of different jobs have unique tendencies in certain language styles and interests. Our results also clearly reveal distinctive levels in terms of Big Five Traits for different jobs. Finally, a classifier is built to predict job types based on the features extracted from tweets. A high accuracy indicates a strong discrimination power of language features for job prediction task.
Inferring Restaurant Styles by Mining Crowd Sourced Photos from User-Review Websites
Nov 19, 2016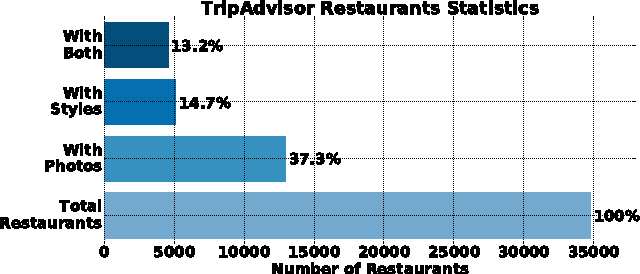

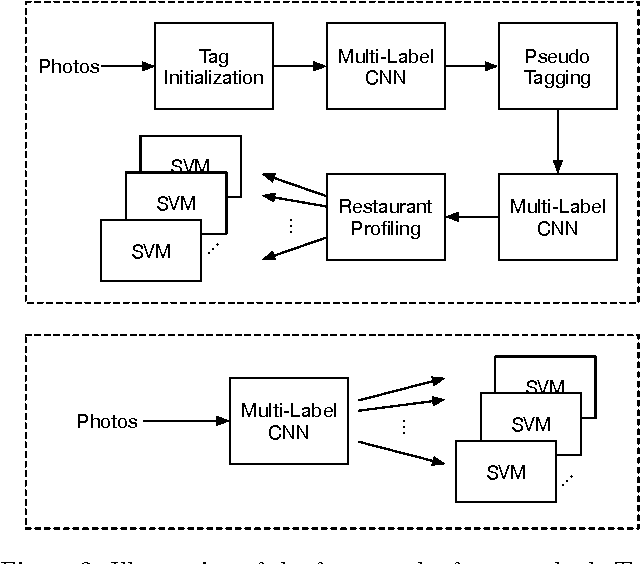

When looking for a restaurant online, user uploaded photos often give people an immediate and tangible impression about a restaurant. Due to their informativeness, such user contributed photos are leveraged by restaurant review websites to provide their users an intuitive and effective search experience. In this paper, we present a novel approach to inferring restaurant types or styles (ambiance, dish styles, suitability for different occasions) from user uploaded photos on user-review websites. To that end, we first collect a novel restaurant photo dataset associating the user contributed photos with the restaurant styles from TripAdvior. We then propose a deep multi-instance multi-label learning (MIML) framework to deal with the unique problem setting of the restaurant style classification task. We employ a two-step bootstrap strategy to train a multi-label convolutional neural network (CNN). The multi-label CNN is then used to compute the confidence scores of restaurant styles for all the images associated with a restaurant. The computed confidence scores are further used to train a final binary classifier for each restaurant style tag. Upon training, the styles of a restaurant can be profiled by analyzing restaurant photos with the trained multi-label CNN and SVM models. Experimental evaluation has demonstrated that our crowd sourcing-based approach can effectively infer the restaurant style when there are a sufficient number of user uploaded photos for a given restaurant.
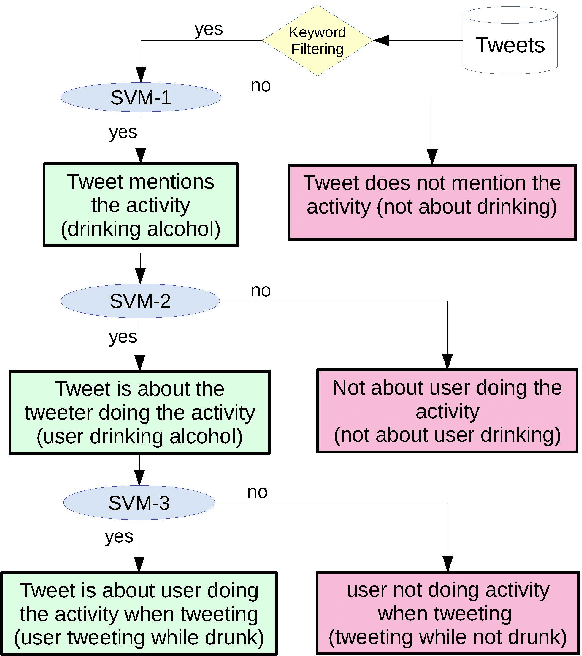
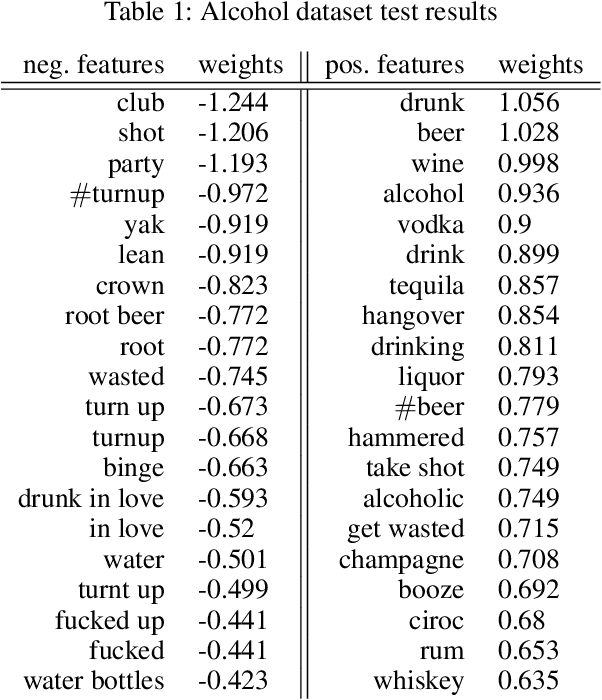
Inferring Fine-grained Details on User Activities and Home Location from Social Media: Detecting Drinking-While-Tweeting Patterns in Communities
Mar 10, 2016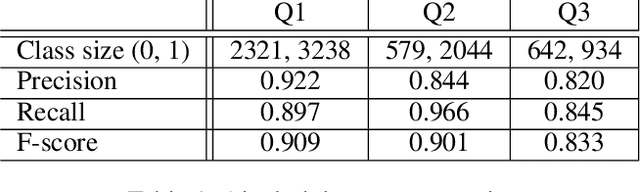
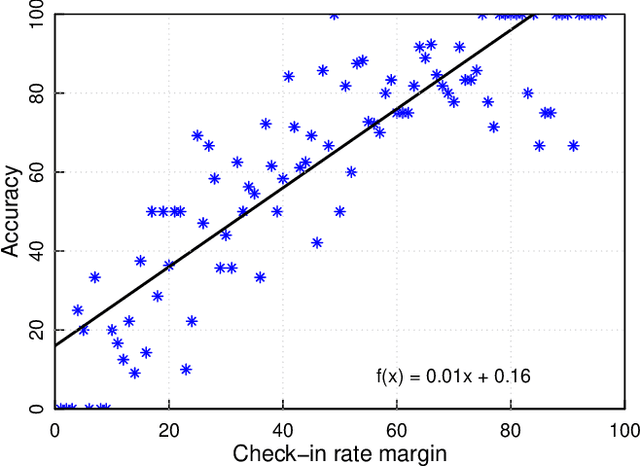
Nearly all previous work on geo-locating latent states and activities from social media confounds general discussions about activities, self-reports of users participating in those activities at times in the past or future, and self-reports made at the immediate time and place the activity occurs. Activities, such as alcohol consumption, may occur at different places and types of places, and it is important not only to detect the local regions where these activities occur, but also to analyze the degree of participation in them by local residents. In this paper, we develop new machine learning based methods for fine-grained localization of activities and home locations from Twitter data. We apply these methods to discover and compare alcohol consumption patterns in a large urban area, New York City, and a more suburban and rural area, Monroe County. We find positive correlations between the rate of alcohol consumption reported among a community's Twitter users and the density of alcohol outlets, demonstrating that the degree of correlation varies significantly between urban and suburban areas. While our experiments are focused on alcohol use, our methods for locating homes and distinguishing temporally-specific self-reports are applicable to a broad range of behaviors and latent states.