 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePVNet: Point-Voxel Interaction LiDAR Scene Upsampling Via Diffusion Models
Aug 23, 2025Accurate 3D scene understanding in outdoor environments heavily relies on high-quality point clouds. However, LiDAR-scanned data often suffer from extreme sparsity, severely hindering downstream 3D perception tasks. Existing point cloud upsampling methods primarily focus on individual objects, thus demonstrating limited generalization capability for complex outdoor scenes. To address this issue, we propose PVNet, a diffusion model-based point-voxel interaction framework to perform LiDAR point cloud upsampling without dense supervision. Specifically, we adopt the classifier-free guidance-based DDPMs to guide the generation, in which we employ a sparse point cloud as the guiding condition and the synthesized point clouds derived from its nearby frames as the input. Moreover, we design a voxel completion module to refine and complete the coarse voxel features for enriching the feature representation. In addition, we propose a point-voxel interaction module to integrate features from both points and voxels, which efficiently improves the environmental perception capability of each upsampled point. To the best of our knowledge, our approach is the first scene-level point cloud upsampling method supporting arbitrary upsampling rates. Extensive experiments on various benchmarks demonstrate that our method achieves state-of-the-art performance. The source code will be available at https://github.com/chengxianjing/PVNet.
Self-supervised 3D Point Cloud Completion via Multi-view Adversarial Learning
Jul 13, 2024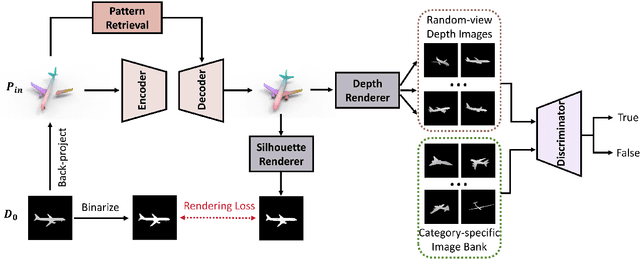
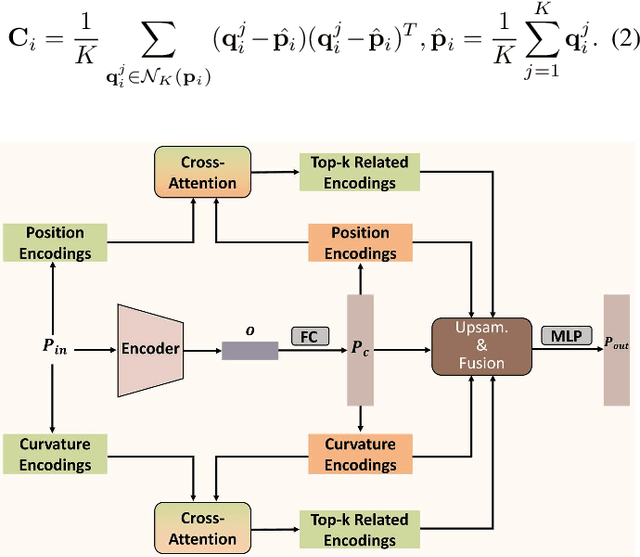

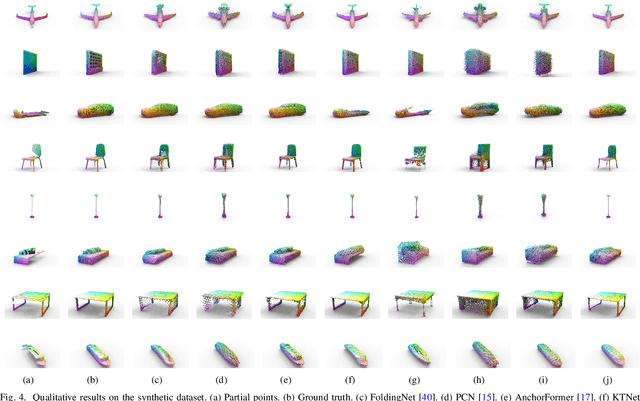
In real-world scenarios, scanned point clouds are often incomplete due to occlusion issues. The task of self-supervised point cloud completion involves reconstructing missing regions of these incomplete objects without the supervision of complete ground truth. Current self-supervised methods either rely on multiple views of partial observations for supervision or overlook the intrinsic geometric similarity that can be identified and utilized from the given partial point clouds. In this paper, we propose MAL-SPC, a framework that effectively leverages both object-level and category-specific geometric similarities to complete missing structures. Our MAL-SPC does not require any 3D complete supervision and only necessitates a single partial point cloud for each object. Specifically, we first introduce a Pattern Retrieval Network to retrieve similar position and curvature patterns between the partial input and the predicted shape, then leverage these similarities to densify and refine the reconstructed results. Additionally, we render the reconstructed complete shape into multi-view depth maps and design an adversarial learning module to learn the geometry of the target shape from category-specific single-view depth images. To achieve anisotropic rendering, we design a density-aware radius estimation algorithm to improve the quality of the rendered images. Our MAL-SPC yields the best results compared to current state-of-the-art methods.We will make the source code publicly available at \url{https://github.com/ltwu6/malspc
The RoboDrive Challenge: Drive Anytime Anywhere in Any Condition
May 14, 2024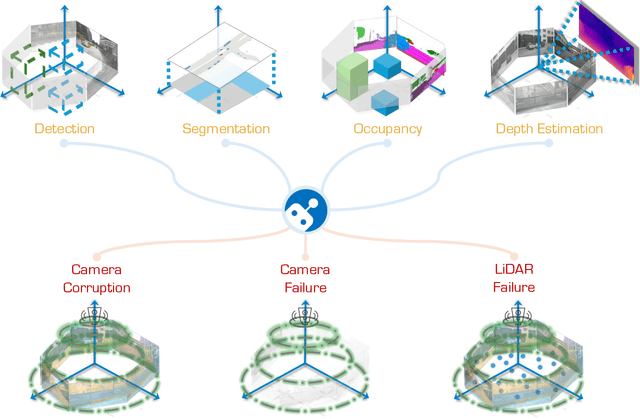


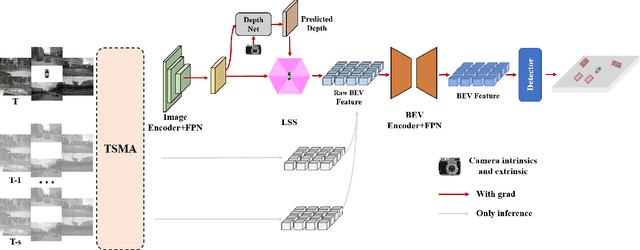
In the realm of autonomous driving, robust perception under out-of-distribution conditions is paramount for the safe deployment of vehicles. Challenges such as adverse weather, sensor malfunctions, and environmental unpredictability can severely impact the performance of autonomous systems. The 2024 RoboDrive Challenge was crafted to propel the development of driving perception technologies that can withstand and adapt to these real-world variabilities. Focusing on four pivotal tasks -- BEV detection, map segmentation, semantic occupancy prediction, and multi-view depth estimation -- the competition laid down a gauntlet to innovate and enhance system resilience against typical and atypical disturbances. This year's challenge consisted of five distinct tracks and attracted 140 registered teams from 93 institutes across 11 countries, resulting in nearly one thousand submissions evaluated through our servers. The competition culminated in 15 top-performing solutions, which introduced a range of innovative approaches including advanced data augmentation, multi-sensor fusion, self-supervised learning for error correction, and new algorithmic strategies to enhance sensor robustness. These contributions significantly advanced the state of the art, particularly in handling sensor inconsistencies and environmental variability. Participants, through collaborative efforts, pushed the boundaries of current technologies, showcasing their potential in real-world scenarios. Extensive evaluations and analyses provided insights into the effectiveness of these solutions, highlighting key trends and successful strategies for improving the resilience of driving perception systems. This challenge has set a new benchmark in the field, providing a rich repository of techniques expected to guide future research in this field.
Global-Supervised Contrastive Loss and View-Aware-Based Post-Processing for Vehicle Re-Identification
Apr 17, 2022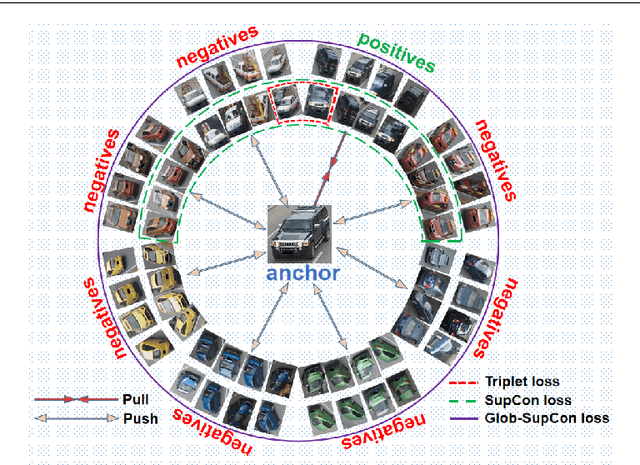
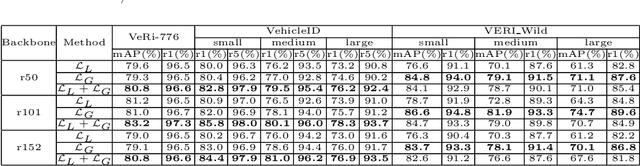


In this paper, we propose a Global-Supervised Contrastive loss and a view-aware-based post-processing (VABPP) method for the field of vehicle re-identification. The traditional supervised contrastive loss calculates the distances of features within the batch, so it has the local attribute. While the proposed Global-Supervised Contrastive loss has new properties and has good global attributes, the positive and negative features of each anchor in the training process come from the entire training set. The proposed VABPP method is the first time that the view-aware-based method is used as a post-processing method in the field of vehicle re-identification. The advantages of VABPP are that, first, it is only used during testing and does not affect the training process. Second, as a post-processing method, it can be easily integrated into other trained re-id models. We directly apply the view-pair distance scaling coefficient matrix calculated by the model trained in this paper to another trained re-id model, and the VABPP method greatly improves its performance, which verifies the feasibility of the VABPP method.