 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-supervised 3D Point Cloud Completion via Multi-view Adversarial Learning
Jul 13, 2024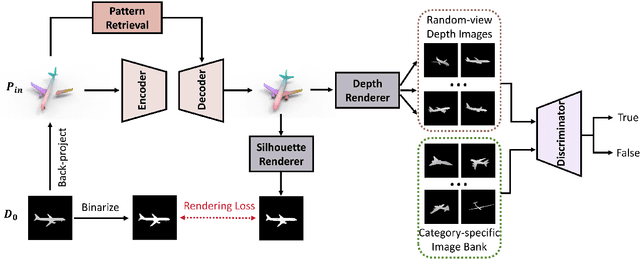
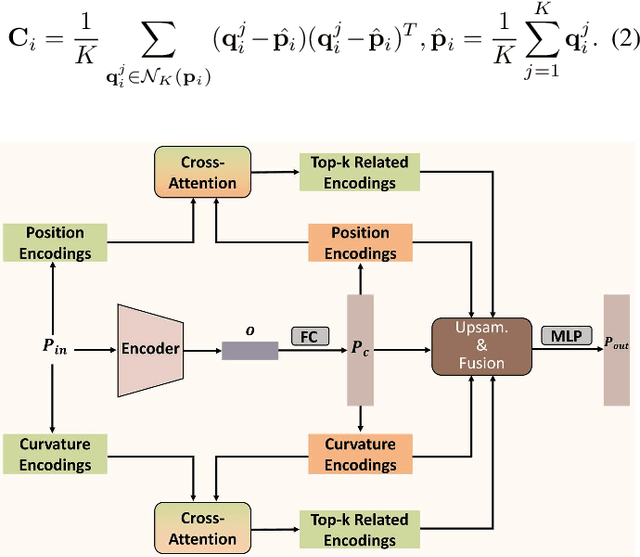

In real-world scenarios, scanned point clouds are often incomplete due to occlusion issues. The task of self-supervised point cloud completion involves reconstructing missing regions of these incomplete objects without the supervision of complete ground truth. Current self-supervised methods either rely on multiple views of partial observations for supervision or overlook the intrinsic geometric similarity that can be identified and utilized from the given partial point clouds. In this paper, we propose MAL-SPC, a framework that effectively leverages both object-level and category-specific geometric similarities to complete missing structures. Our MAL-SPC does not require any 3D complete supervision and only necessitates a single partial point cloud for each object. Specifically, we first introduce a Pattern Retrieval Network to retrieve similar position and curvature patterns between the partial input and the predicted shape, then leverage these similarities to densify and refine the reconstructed results. Additionally, we render the reconstructed complete shape into multi-view depth maps and design an adversarial learning module to learn the geometry of the target shape from category-specific single-view depth images. To achieve anisotropic rendering, we design a density-aware radius estimation algorithm to improve the quality of the rendered images. Our MAL-SPC yields the best results compared to current state-of-the-art methods.We will make the source code publicly available at \url{https://github.com/ltwu6/malspc
3D Shape Completion on Unseen Categories:A Weakly-supervised Approach
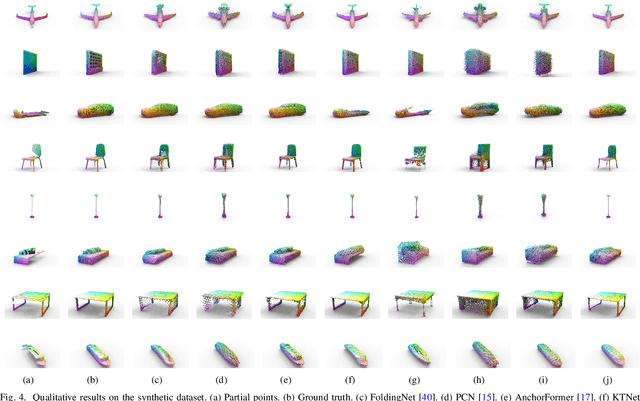
Jan 19, 20243D shapes captured by scanning devices are often incomplete due to occlusion. 3D shape completion methods have been explored to tackle this limitation. However, most of these methods are only trained and tested on a subset of categories, resulting in poor generalization to unseen categories. In this paper, we introduce a novel weakly-supervised framework to reconstruct the complete shapes from unseen categories. We first propose an end-to-end prior-assisted shape learning network that leverages data from the seen categories to infer a coarse shape. Specifically, we construct a prior bank consisting of representative shapes from the seen categories. Then, we design a multi-scale pattern correlation module for learning the complete shape of the input by analyzing the correlation between local patterns within the input and the priors at various scales. In addition, we propose a self-supervised shape refinement model to further refine the coarse shape. Considering the shape variability of 3D objects across categories, we construct a category-specific prior bank to facilitate shape refinement. Then, we devise a voxel-based partial matching loss and leverage the partial scans to drive the refinement process. Extensive experimental results show that our approach is superior to state-of-the-art methods by a large margin.
Leveraging Single-View Images for Unsupervised 3D Point Cloud Completion
Dec 01, 2022Point clouds captured by scanning devices are often incomplete due to occlusion. Point cloud completion aims to predict the complete shape based on its partial input. Existing methods can be classified into supervised and unsupervised methods. However, both of them require a large number of 3D complete point clouds, which are difficult to capture. In this paper, we propose Cross-PCC, an unsupervised point cloud completion method without requiring any 3D complete point clouds. We only utilize 2D images of the complete objects, which are easier to capture than 3D complete and clean point clouds. Specifically, to take advantage of the complementary information from 2D images, we use a single-view RGB image to extract 2D features and design a fusion module to fuse the 2D and 3D features extracted from the partial point cloud. To guide the shape of predicted point clouds, we project the predicted points of the object to the 2D plane and use the foreground pixels of its silhouette maps to constrain the position of the projected points. To reduce the outliers of the predicted point clouds, we propose a view calibrator to move the points projected to the background into the foreground by the single-view silhouette image. To the best of our knowledge, our approach is the first point cloud completion method that does not require any 3D supervision. The experimental results of our method are superior to those of the state-of-the-art unsupervised methods by a large margin. Moreover, compared to some supervised methods, our method achieves similar performance. We will make the source code publicly available at https://github.com/ltwu6/cross-pcc.