 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAcc3D: Accelerating Single Image to 3D Diffusion Models via Edge Consistency Guided Score Distillation
Mar 20, 2025

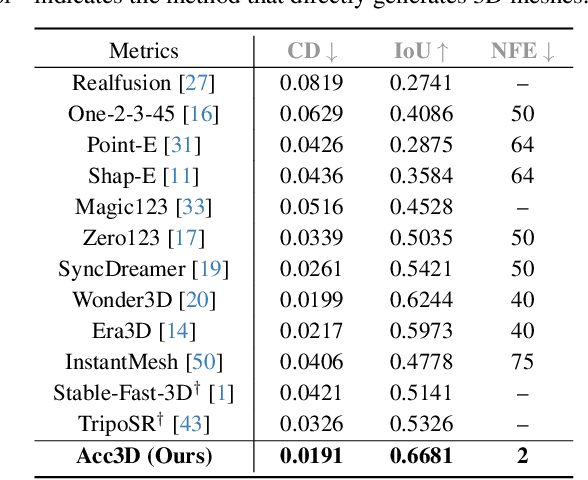

We present Acc3D to tackle the challenge of accelerating the diffusion process to generate 3D models from single images. To derive high-quality reconstructions through few-step inferences, we emphasize the critical issue of regularizing the learning of score function in states of random noise. To this end, we propose edge consistency, i.e., consistent predictions across the high signal-to-noise ratio region, to enhance a pre-trained diffusion model, enabling a distillation-based refinement of the endpoint score function. Building on those distilled diffusion models, we propose an adversarial augmentation strategy to further enrich the generation detail and boost overall generation quality. The two modules complement each other, mutually reinforcing to elevate generative performance. Extensive experiments demonstrate that our Acc3D not only achieves over a $20\times$ increase in computational efficiency but also yields notable quality improvements, compared to the state-of-the-arts.
PrefPaint: Aligning Image Inpainting Diffusion Model with Human Preference
Oct 29, 2024
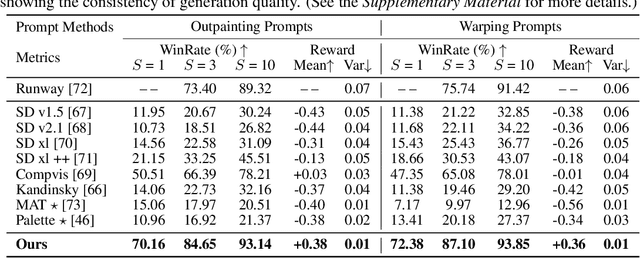
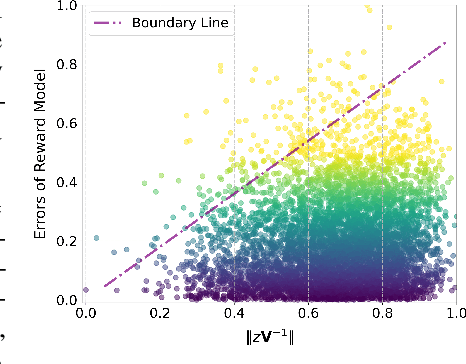
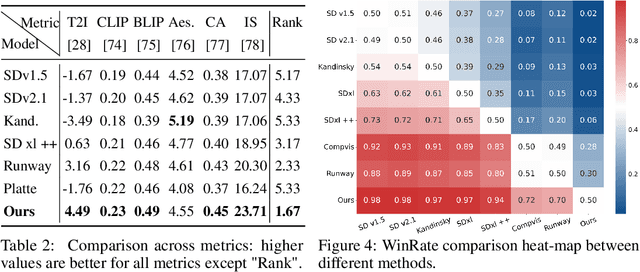
In this paper, we make the first attempt to align diffusion models for image inpainting with human aesthetic standards via a reinforcement learning framework, significantly improving the quality and visual appeal of inpainted images. Specifically, instead of directly measuring the divergence with paired images, we train a reward model with the dataset we construct, consisting of nearly 51,000 images annotated with human preferences. Then, we adopt a reinforcement learning process to fine-tune the distribution of a pre-trained diffusion model for image inpainting in the direction of higher reward. Moreover, we theoretically deduce the upper bound on the error of the reward model, which illustrates the potential confidence of reward estimation throughout the reinforcement alignment process, thereby facilitating accurate regularization. Extensive experiments on inpainting comparison and downstream tasks, such as image extension and 3D reconstruction, demonstrate the effectiveness of our approach, showing significant improvements in the alignment of inpainted images with human preference compared with state-of-the-art methods. This research not only advances the field of image inpainting but also provides a framework for incorporating human preference into the iterative refinement of generative models based on modeling reward accuracy, with broad implications for the design of visually driven AI applications. Our code and dataset are publicly available at https://prefpaint.github.io.
Learning from Pixel-Level Noisy Label : A New Perspective for Light Field Saliency Detection
Apr 28, 2022

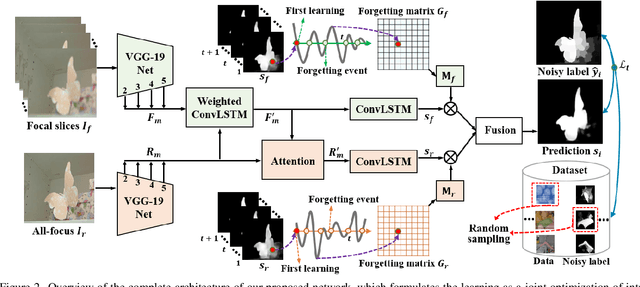
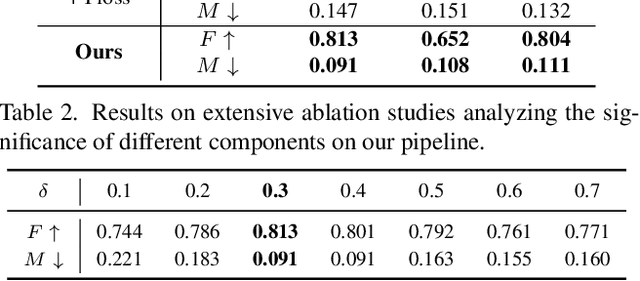
Saliency detection with light field images is becoming attractive given the abundant cues available, however, this comes at the expense of large-scale pixel level annotated data which is expensive to generate. In this paper, we propose to learn light field saliency from pixel-level noisy labels obtained from unsupervised hand crafted featured based saliency methods. Given this goal, a natural question is: can we efficiently incorporate the relationships among light field cues while identifying clean labels in a unified framework? We address this question by formulating the learning as a joint optimization of intra light field features fusion stream and inter scenes correlation stream to generate the predictions. Specially, we first introduce a pixel forgetting guided fusion module to mutually enhance the light field features and exploit pixel consistency across iterations to identify noisy pixels. Next, we introduce a cross scene noise penalty loss for better reflecting latent structures of training data and enabling the learning to be invariant to noise. Extensive experiments on multiple benchmark datasets demonstrate the superiority of our framework showing that it learns saliency prediction comparable to state-of-the-art fully supervised light field saliency methods. Our code is available at https://github.com/OLobbCode/NoiseLF.