 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Reward Design for Reinforcement Learning in Complex Robotic Tasks
Dec 14, 2024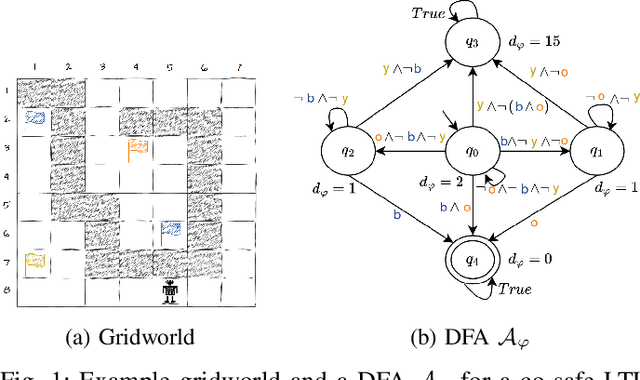
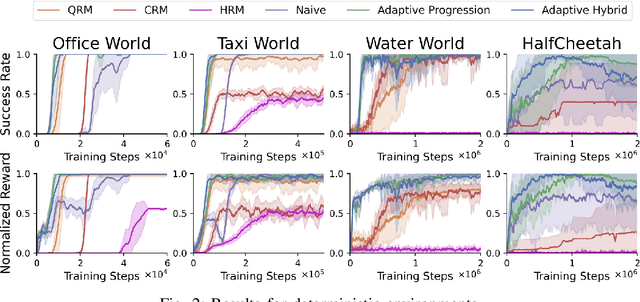
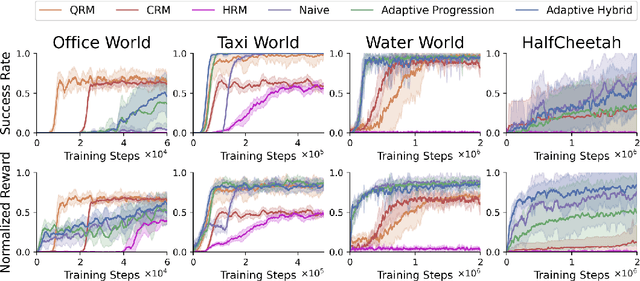
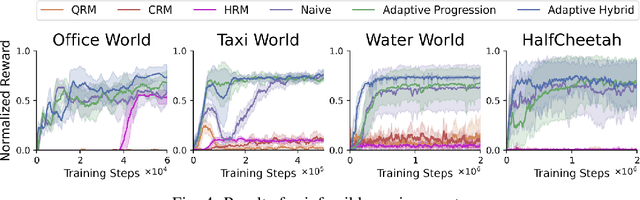
There is a surge of interest in using formal languages such as Linear Temporal Logic (LTL) and finite automata to precisely and succinctly specify complex tasks and derive reward functions for reinforcement learning (RL) in robotic applications. However, existing methods often assign sparse rewards (e.g., giving a reward of 1 only if a task is completed and 0 otherwise), necessitating extensive exploration to converge to a high-quality policy. To address this limitation, we propose a suite of reward functions that incentivize an RL agent to make measurable progress on tasks specified by LTL formulas and develop an adaptive reward shaping approach that dynamically updates these reward functions during the learning process. Experimental results on a range of RL-based robotic tasks demonstrate that the proposed approach is compatible with various RL algorithms and consistently outperforms baselines, achieving earlier convergence to better policies with higher task success rates and returns.
Logic-based Reward Shaping for Multi-Agent Reinforcement Learning
Jun 17, 2022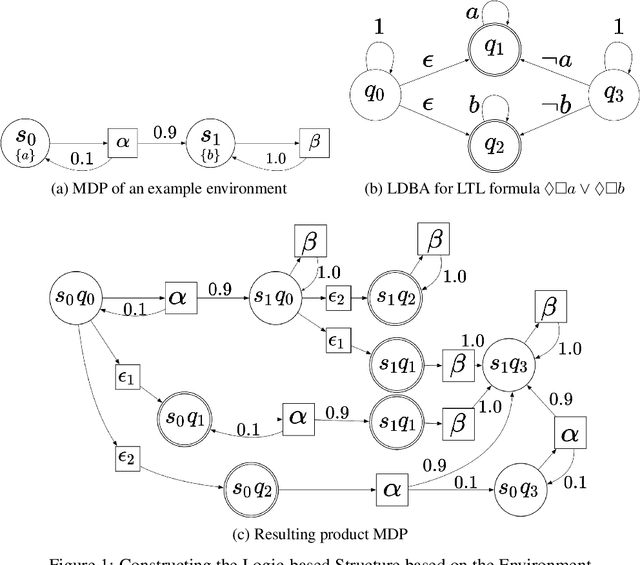
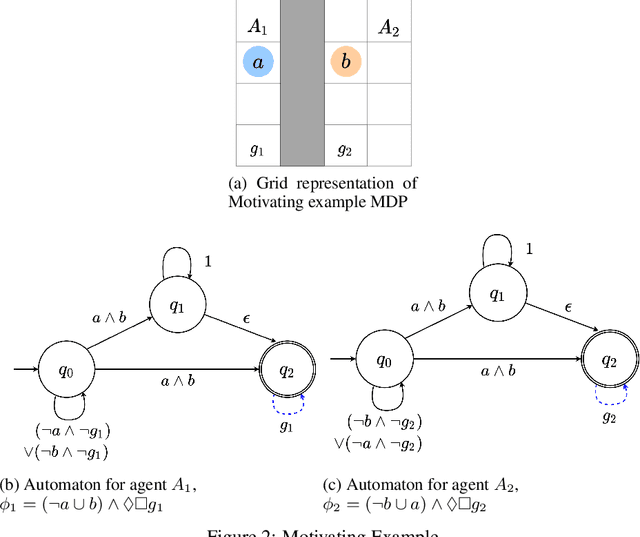
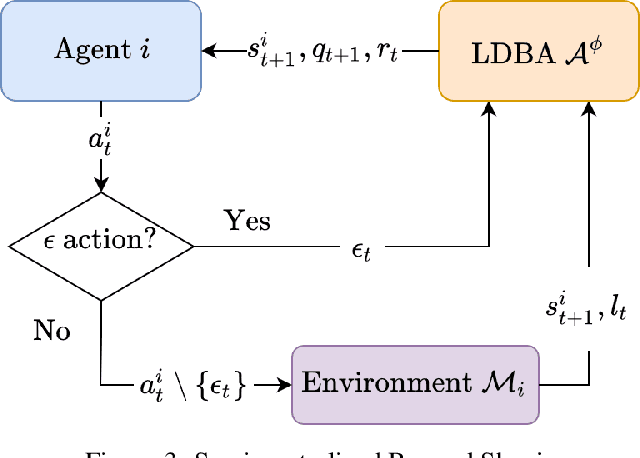
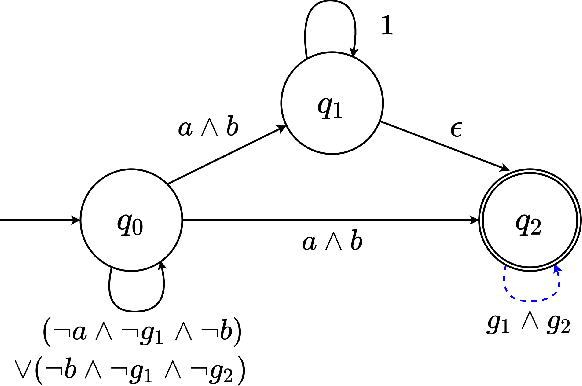
Reinforcement learning (RL) relies heavily on exploration to learn from its environment and maximize observed rewards. Therefore, it is essential to design a reward function that guarantees optimal learning from the received experience. Previous work has combined automata and logic based reward shaping with environment assumptions to provide an automatic mechanism to synthesize the reward function based on the task. However, there is limited work on how to expand logic-based reward shaping to Multi-Agent Reinforcement Learning (MARL). The environment will need to consider the joint state in order to keep track of other agents if the task requires cooperation, thus suffering from the curse of dimensionality with respect to the number of agents. This project explores how logic-based reward shaping for MARL can be designed for different scenarios and tasks. We present a novel method for semi-centralized logic-based MARL reward shaping that is scalable in the number of agents and evaluate it in multiple scenarios.