 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReasoning, Memorization, and Fine-Tuning Language Models for Non-Cooperative Games
Oct 18, 2024


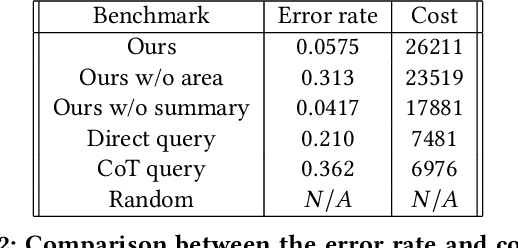
We develop a method that integrates the tree of thoughts and multi-agent framework to enhance the capability of pre-trained language models in solving complex, unfamiliar games. The method decomposes game-solving into four incremental tasks -- game summarization, area selection, action extraction, and action validation -- each assigned to a specific language-model agent. By constructing a tree of thoughts, the method simulates reasoning paths and allows agents to collaboratively distill game representations and tactics, mitigating the limitations of language models in reasoning and long-term memorization. Additionally, an automated fine-tuning process further optimizes the agents' performance by ranking query-response pairs based on game outcomes, e.g., winning or losing. We apply the method to a non-cooperative game and demonstrate a 65 percent winning rate against benchmark algorithms, with an additional 10 percent improvement after fine-tuning. In contrast to existing deep learning algorithms for game solving that require millions of training samples, the proposed method consumes approximately 1000 training samples, highlighting its efficiency and scalability.