 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAudio Classification of Low Feature Spectrograms Utilizing Convolutional Neural Networks
Paper and Code
Oct 28, 2024
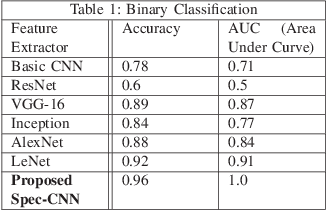

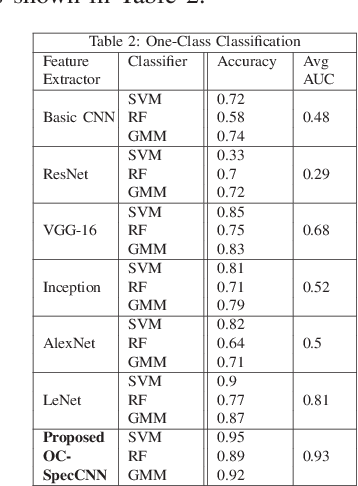
Modern day audio signal classification techniques lack the ability to classify low feature audio signals in the form of spectrographic temporal frequency data representations. Additionally, currently utilized techniques rely on full diverse data sets that are often not representative of real-world distributions. This paper derives several first-of-its-kind machine learning methodologies to analyze these low feature audio spectrograms given data distributions that may have normalized, skewed, or even limited training sets. In particular, this paper proposes several novel customized convolutional architectures to extract identifying features using binary, one-class, and siamese approaches to identify the spectrographic signature of a given audio signal. Utilizing these novel convolutional architectures as well as the proposed classification methods, these experiments demonstrate state-of-the-art classification accuracy and improved efficiency than traditional audio classification methods.