 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVoice Conversion Can Improve ASR in Very Low-Resource Settings
Paper and Code
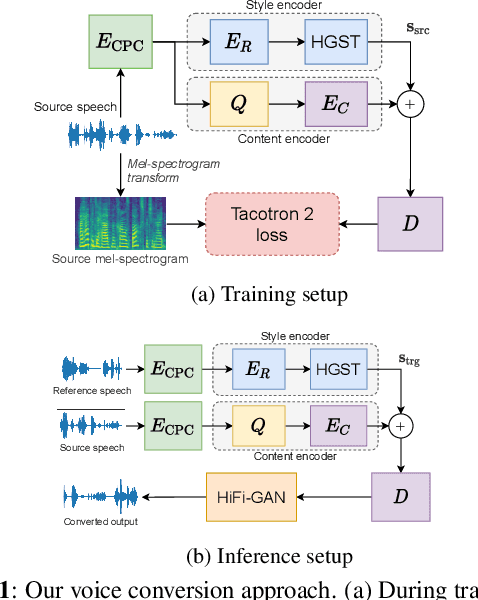
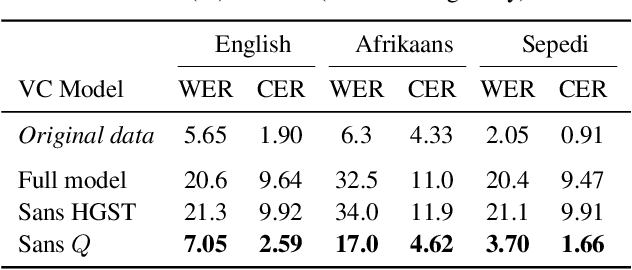
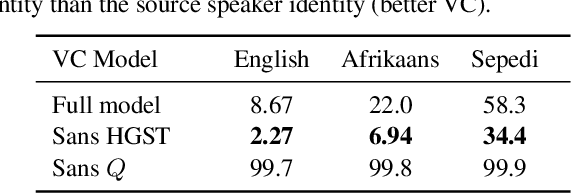

Voice conversion (VC) has been proposed to improve speech recognition systems in low-resource languages by using it to augment limited training data. But until recently, practical issues such as compute speed have limited the use of VC for this purpose. Moreover, it is still unclear whether a VC model trained on one well-resourced language can be applied to speech from another low-resource language for the purpose of data augmentation. In this work we assess whether a VC system can be used cross-lingually to improve low-resource speech recognition. Concretely, we combine several recent techniques to design and train a practical VC system in English, and then use this system to augment data for training a speech recognition model in several low-resource languages. We find that when using a sensible amount of augmented data, speech recognition performance is improved in all four low-resource languages considered.