 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGAN You Hear Me? Reclaiming Unconditional Speech Synthesis from Diffusion Models
Paper and Code

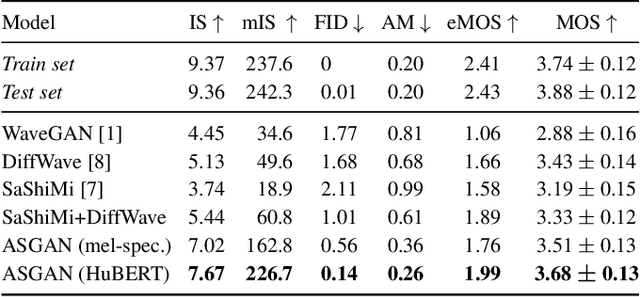
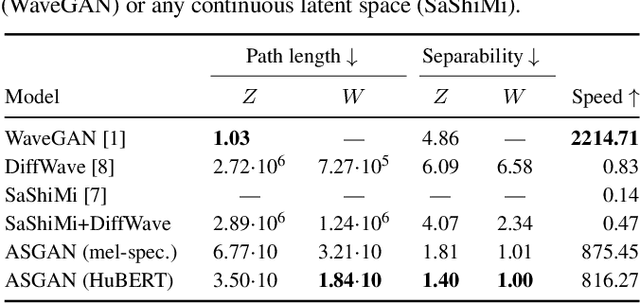
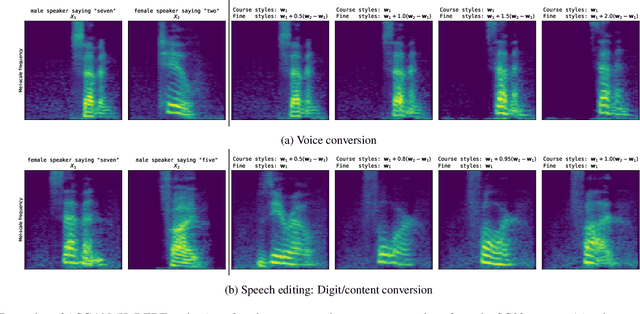
We propose AudioStyleGAN (ASGAN), a new generative adversarial network (GAN) for unconditional speech synthesis. As in the StyleGAN family of image synthesis models, ASGAN maps sampled noise to a disentangled latent vector which is then mapped to a sequence of audio features so that signal aliasing is suppressed at every layer. To successfully train ASGAN, we introduce a number of new techniques, including a modification to adaptive discriminator augmentation to probabilistically skip discriminator updates. ASGAN achieves state-of-the-art results in unconditional speech synthesis on the Google Speech Commands dataset. It is also substantially faster than the top-performing diffusion models. Through a design that encourages disentanglement, ASGAN is able to perform voice conversion and speech editing without being explicitly trained to do so. ASGAN demonstrates that GANs are still highly competitive with diffusion models. Code, models, samples: https://github.com/RF5/simple-asgan/.