 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransFusion: Transcribing Speech with Multinomial Diffusion
Paper and Code
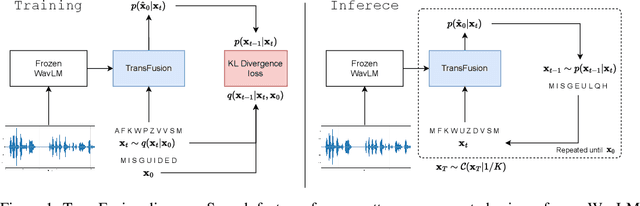
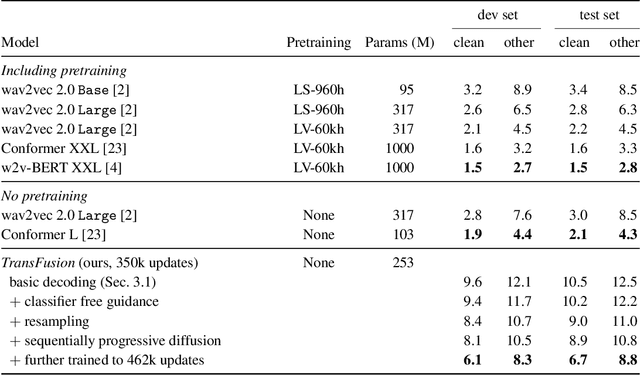
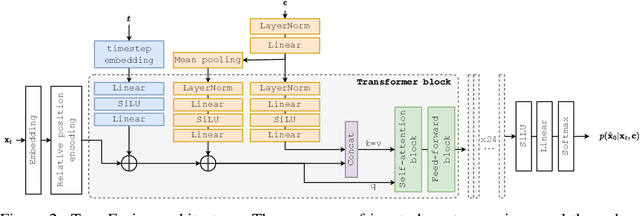
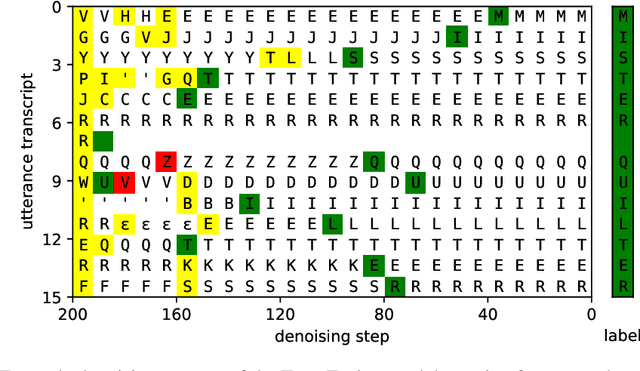
Diffusion models have shown exceptional scaling properties in the image synthesis domain, and initial attempts have shown similar benefits for applying diffusion to unconditional text synthesis. Denoising diffusion models attempt to iteratively refine a sampled noise signal until it resembles a coherent signal (such as an image or written sentence). In this work we aim to see whether the benefits of diffusion models can also be realized for speech recognition. To this end, we propose a new way to perform speech recognition using a diffusion model conditioned on pretrained speech features. Specifically, we propose TransFusion: a transcribing diffusion model which iteratively denoises a random character sequence into coherent text corresponding to the transcript of a conditioning utterance. We demonstrate comparable performance to existing high-performing contrastive models on the LibriSpeech speech recognition benchmark. To the best of our knowledge, we are the first to apply denoising diffusion to speech recognition. We also propose new techniques for effectively sampling and decoding multinomial diffusion models. These are required because traditional methods of sampling from acoustic models are not possible with our new discrete diffusion approach. Code and trained models are available: https://github.com/RF5/transfusion-asr