 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards visually prompted keyword localisation for zero-resource spoken languages
Paper and Code
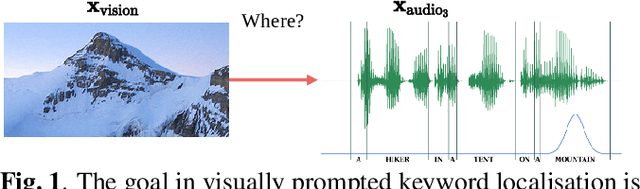
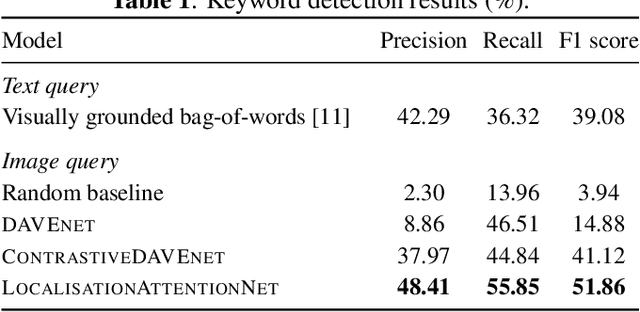
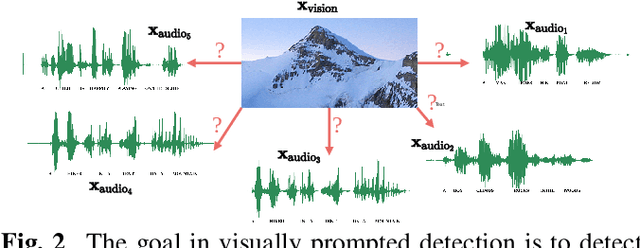
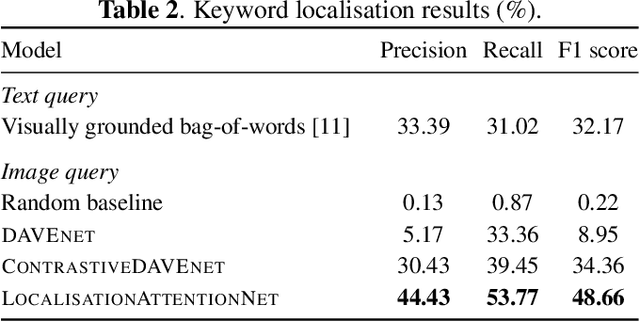
Imagine being able to show a system a visual depiction of a keyword and finding spoken utterances that contain this keyword from a zero-resource speech corpus. We formalise this task and call it visually prompted keyword localisation (VPKL): given an image of a keyword, detect and predict where in an utterance the keyword occurs. To do VPKL, we propose a speech-vision model with a novel localising attention mechanism which we train with a new keyword sampling scheme. We show that these innovations give improvements in VPKL over an existing speech-vision model. We also compare to a visual bag-of-words (BoW) model where images are automatically tagged with visual labels and paired with unlabelled speech. Although this visual BoW can be queried directly with a written keyword (while our's takes image queries), our new model still outperforms the visual BoW in both detection and localisation, giving a 16% relative improvement in localisation F1.