 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised feature learning for speech using correspondence and Siamese networks
Mar 28, 2020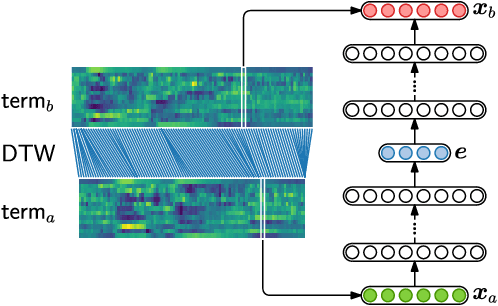
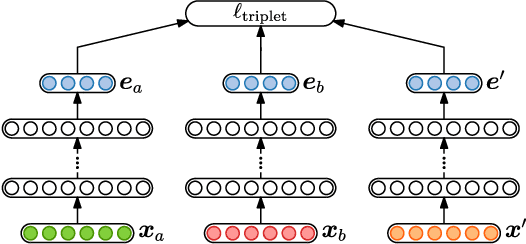
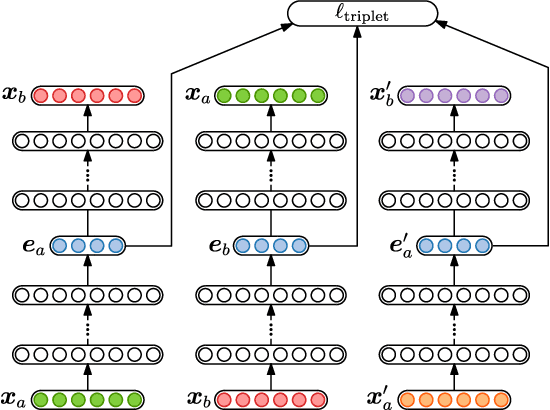
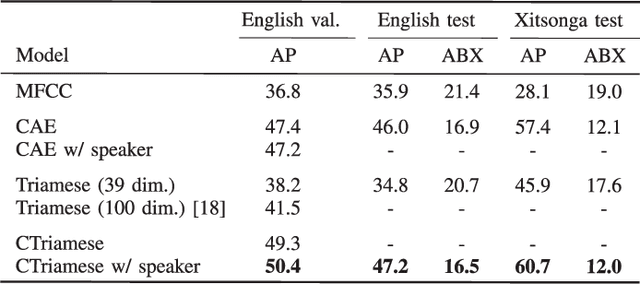
In zero-resource settings where transcribed speech audio is unavailable, unsupervised feature learning is essential for downstream speech processing tasks. Here we compare two recent methods for frame-level acoustic feature learning. For both methods, unsupervised term discovery is used to find pairs of word examples of the same unknown type. Dynamic programming is then used to align the feature frames between each word pair, serving as weak top-down supervision for the two models. For the correspondence autoencoder (CAE), matching frames are presented as input-output pairs. The Triamese network uses a contrastive loss to reduce the distance between frames of the same predicted word type while increasing the distance between negative examples. For the first time, these feature extractors are compared on the same discrimination tasks using the same weak supervision pairs. We find that, on the two datasets considered here, the CAE outperforms the Triamese network. However, we show that a new hybrid correspondence-Triamese approach (CTriamese), consistently outperforms both the CAE and Triamese models in terms of average precision and ABX error rates on both English and Xitsonga evaluation data.
* 5 pages, 3 figures, 2 tables; accepted to the IEEE Signal Processing Letters, (c) 2020 IEEE