 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeControl-Aware Prediction Objectives for Autonomous Driving
Apr 28, 2022
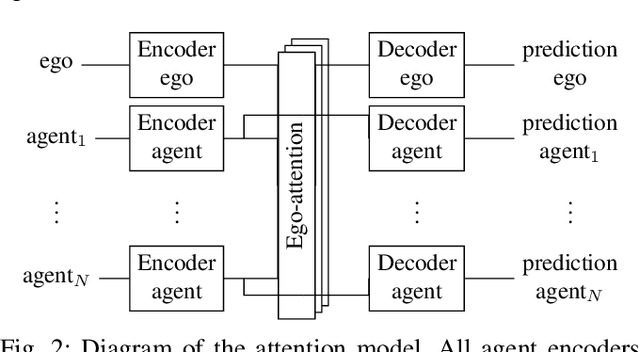
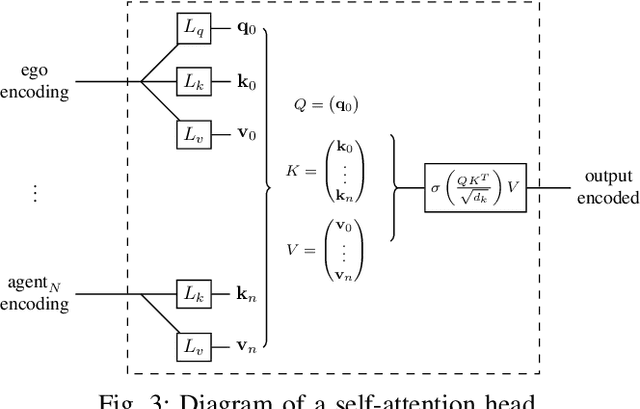

Autonomous vehicle software is typically structured as a modular pipeline of individual components (e.g., perception, prediction, and planning) to help separate concerns into interpretable sub-tasks. Even when end-to-end training is possible, each module has its own set of objectives used for safety assurance, sample efficiency, regularization, or interpretability. However, intermediate objectives do not always align with overall system performance. For example, optimizing the likelihood of a trajectory prediction module might focus more on easy-to-predict agents than safety-critical or rare behaviors (e.g., jaywalking). In this paper, we present control-aware prediction objectives (CAPOs), to evaluate the downstream effect of predictions on control without requiring the planner be differentiable. We propose two types of importance weights that weight the predictive likelihood: one using an attention model between agents, and another based on control variation when exchanging predicted trajectories for ground truth trajectories. Experimentally, we show our objectives improve overall system performance in suburban driving scenarios using the CARLA simulator.
Dynamics-Aware Comparison of Learned Reward Functions
Jan 25, 2022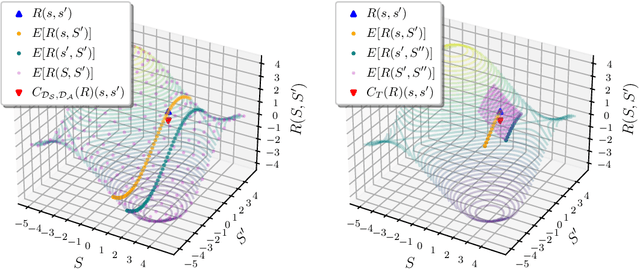
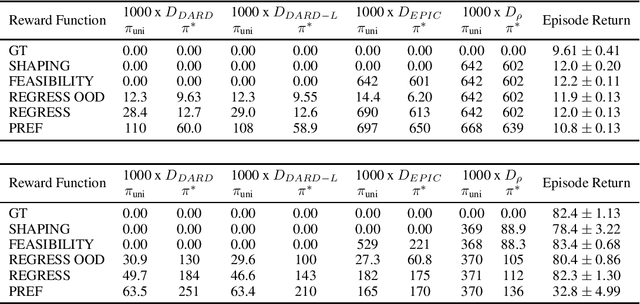
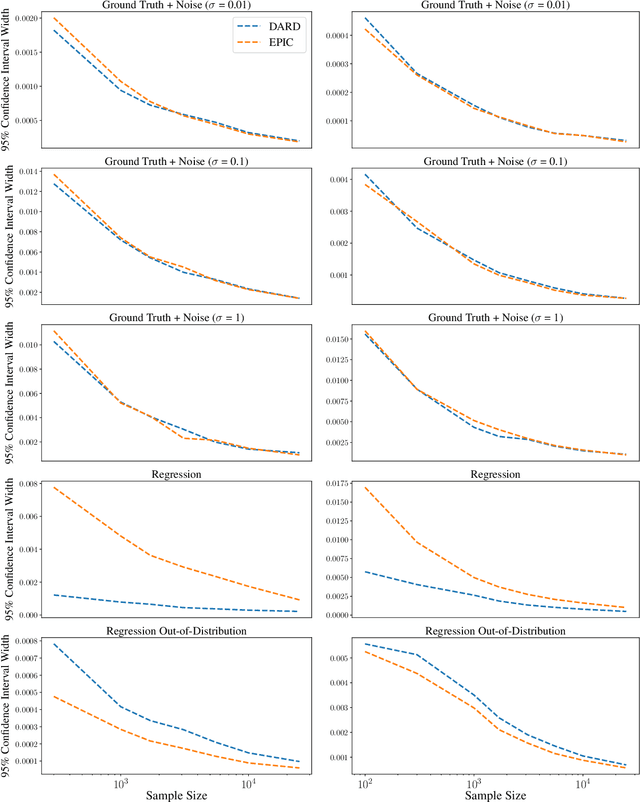
The ability to learn reward functions plays an important role in enabling the deployment of intelligent agents in the real world. However, comparing reward functions, for example as a means of evaluating reward learning methods, presents a challenge. Reward functions are typically compared by considering the behavior of optimized policies, but this approach conflates deficiencies in the reward function with those of the policy search algorithm used to optimize it. To address this challenge, Gleave et al. (2020) propose the Equivalent-Policy Invariant Comparison (EPIC) distance. EPIC avoids policy optimization, but in doing so requires computing reward values at transitions that may be impossible under the system dynamics. This is problematic for learned reward functions because it entails evaluating them outside of their training distribution, resulting in inaccurate reward values that we show can render EPIC ineffective at comparing rewards. To address this problem, we propose the Dynamics-Aware Reward Distance (DARD), a new reward pseudometric. DARD uses an approximate transition model of the environment to transform reward functions into a form that allows for comparisons that are invariant to reward shaping while only evaluating reward functions on transitions close to their training distribution. Experiments in simulated physical domains demonstrate that DARD enables reliable reward comparisons without policy optimization and is significantly more predictive than baseline methods of downstream policy performance when dealing with learned reward functions.