 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGrounded Situation Recognition
Paper and Code
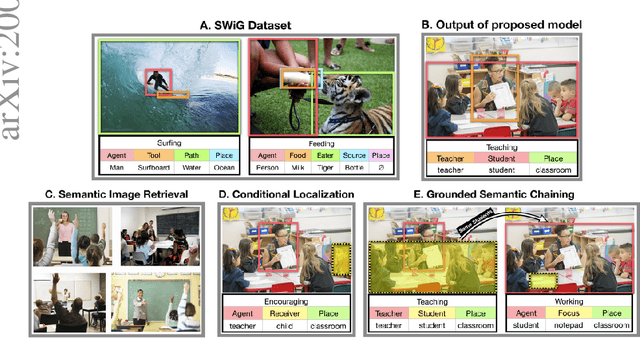
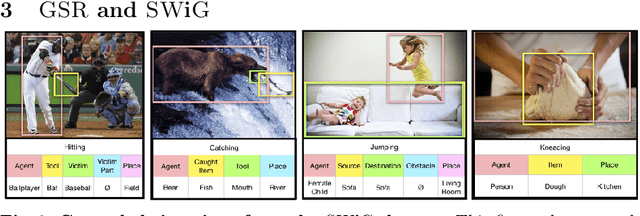

We introduce Grounded Situation Recognition (GSR), a task that requires producing structured semantic summaries of images describing: the primary activity, entities engaged in the activity with their roles (e.g. agent, tool), and bounding-box groundings of entities. GSR presents important technical challenges: identifying semantic saliency, categorizing and localizing a large and diverse set of entities, overcoming semantic sparsity, and disambiguating roles. Moreover, unlike in captioning, GSR is straightforward to evaluate. To study this new task we create the Situations With Groundings (SWiG) dataset which adds 278,336 bounding-box groundings to the 11,538 entity classes in the imsitu dataset. We propose a Joint Situation Localizer and find that jointly predicting situations and groundings with end-to-end training handily outperforms independent training on the entire grounding metric suite with relative gains between 8% and 32%. Finally, we show initial findings on three exciting future directions enabled by our models: conditional querying, visual chaining, and grounded semantic aware image retrieval. Code and data available at https://prior.allenai.org/projects/gsr.