 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero- and Few-Shots Knowledge Graph Triplet Extraction with Large Language Models
Dec 04, 2023In this work, we tested the Triplet Extraction (TE) capabilities of a variety of Large Language Models (LLMs) of different sizes in the Zero- and Few-Shots settings. In detail, we proposed a pipeline that dynamically gathers contextual information from a Knowledge Base (KB), both in the form of context triplets and of (sentence, triplets) pairs as examples, and provides it to the LLM through a prompt. The additional context allowed the LLMs to be competitive with all the older fully trained baselines based on the Bidirectional Long Short-Term Memory (BiLSTM) Network architecture. We further conducted a detailed analysis of the quality of the gathered KB context, finding it to be strongly correlated with the final TE performance of the model. In contrast, the size of the model appeared to only logarithmically improve the TE capabilities of the LLMs.
Modelling conditional probabilities with Riemann-Theta Boltzmann Machines
May 27, 2019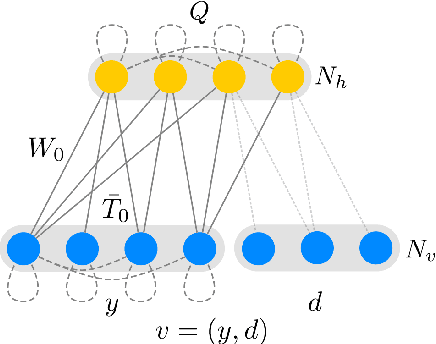

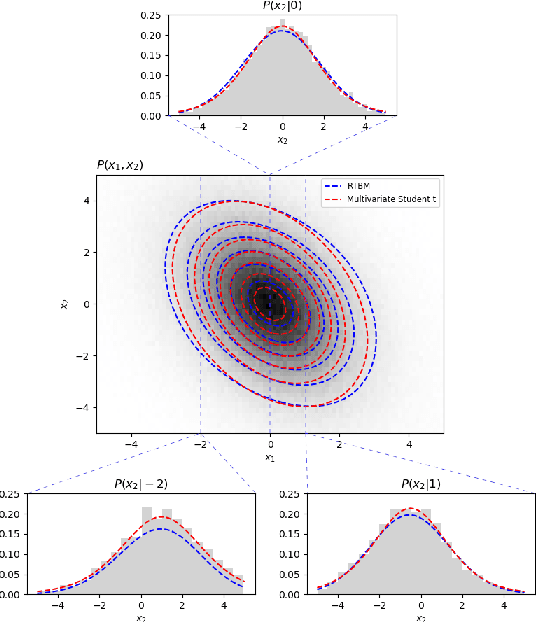
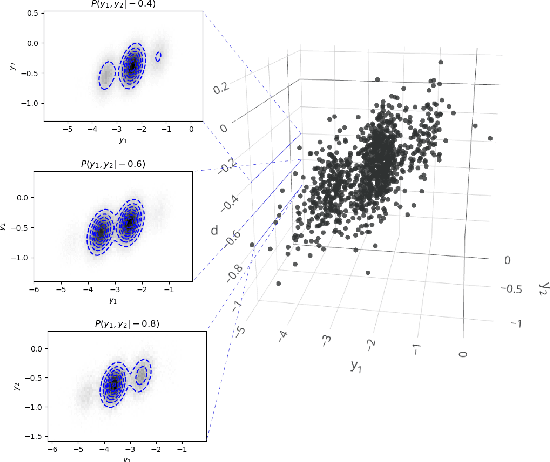
The probability density function for the visible sector of a Riemann-Theta Boltzmann machine can be taken conditional on a subset of the visible units. We derive that the corresponding conditional density function is given by a reparameterization of the Riemann-Theta Boltzmann machine modelling the original probability density function. Therefore the conditional densities can be directly inferred from the Riemann-Theta Boltzmann machine.