 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepHGNN: Study of Graph Neural Network based Forecasting Methods for Hierarchically Related Multivariate Time Series
May 29, 2024Graph Neural Networks (GNN) have gained significant traction in the forecasting domain, especially for their capacity to simultaneously account for intra-series temporal correlations and inter-series relationships. This paper introduces a novel Hierarchical GNN (DeepHGNN) framework, explicitly designed for forecasting in complex hierarchical structures. The uniqueness of DeepHGNN lies in its innovative graph-based hierarchical interpolation and an end-to-end reconciliation mechanism. This approach ensures forecast accuracy and coherence across various hierarchical levels while sharing signals across them, addressing a key challenge in hierarchical forecasting. A critical insight in hierarchical time series is the variance in forecastability across levels, with upper levels typically presenting more predictable components. DeepHGNN capitalizes on this insight by pooling and leveraging knowledge from all hierarchy levels, thereby enhancing the overall forecast accuracy. Our comprehensive evaluation set against several state-of-the-art models confirm the superior performance of DeepHGNN. This research not only demonstrates DeepHGNN's effectiveness in achieving significantly improved forecast accuracy but also contributes to the understanding of graph-based methods in hierarchical time series forecasting.
Adaptive Dependency Learning Graph Neural Networks
Dec 06, 2023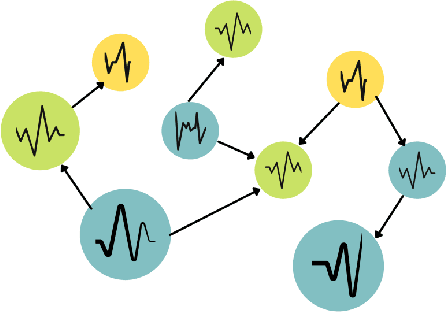
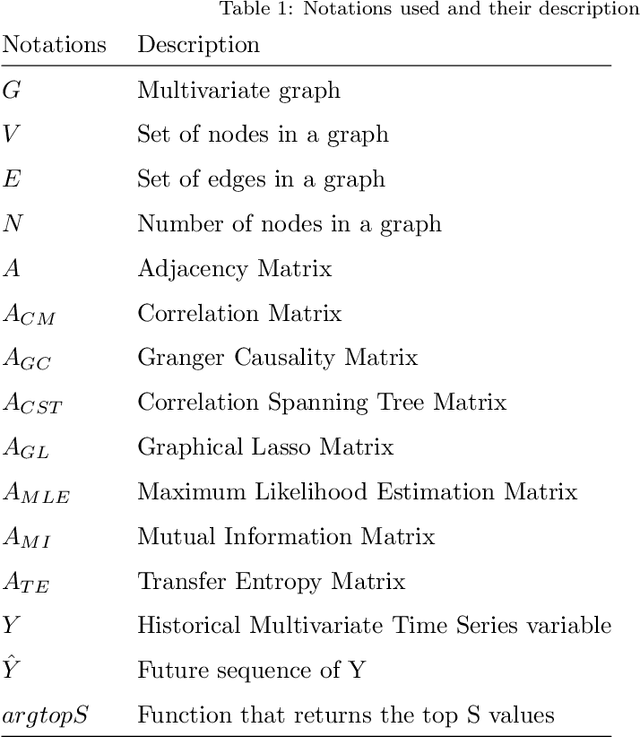
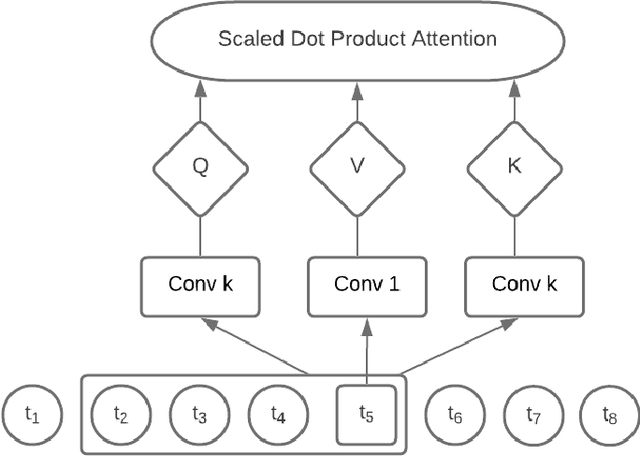
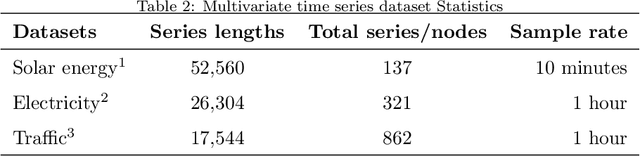
Graph Neural Networks (GNN) have recently gained popularity in the forecasting domain due to their ability to model complex spatial and temporal patterns in tasks such as traffic forecasting and region-based demand forecasting. Most of these methods require a predefined graph as input, whereas in real-life multivariate time series problems, a well-predefined dependency graph rarely exists. This requirement makes it harder for GNNs to be utilised widely for multivariate forecasting problems in other domains such as retail or energy. In this paper, we propose a hybrid approach combining neural networks and statistical structure learning models to self-learn the dependencies and construct a dynamically changing dependency graph from multivariate data aiming to enable the use of GNNs for multivariate forecasting even when a well-defined graph does not exist. The statistical structure modeling in conjunction with neural networks provides a well-principled and efficient approach by bringing in causal semantics to determine dependencies among the series. Finally, we demonstrate significantly improved performance using our proposed approach on real-world benchmark datasets without a pre-defined dependency graph.
Learning to Continually Learn Rapidly from Few and Noisy Data
Mar 06, 2021



Neural networks suffer from catastrophic forgetting and are unable to sequentially learn new tasks without guaranteed stationarity in data distribution. Continual learning could be achieved via replay -- by concurrently training externally stored old data while learning a new task. However, replay becomes less effective when each past task is allocated with less memory. To overcome this difficulty, we supplemented replay mechanics with meta-learning for rapid knowledge acquisition. By employing a meta-learner, which \textit{learns a learning rate per parameter per past task}, we found that base learners produced strong results when less memory was available. Additionally, our approach inherited several meta-learning advantages for continual learning: it demonstrated strong robustness to continually learn under the presence of noises and yielded base learners to higher accuracy in less updates.
MTL2L: A Context Aware Neural Optimiser
Jul 18, 2020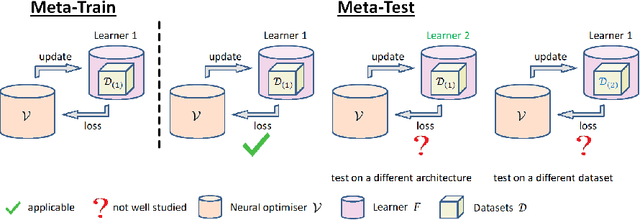

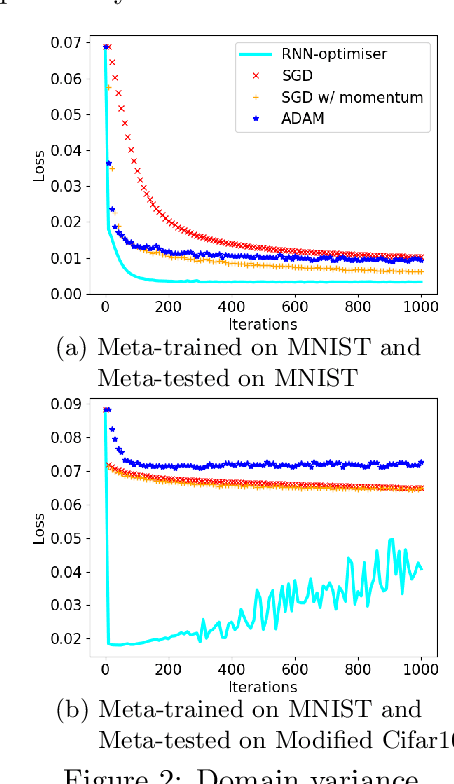
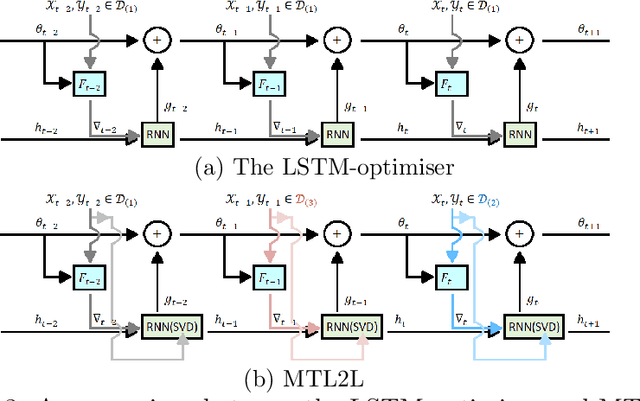
Learning to learn (L2L) trains a meta-learner to assist the learning of a task-specific base learner. Previously, it was shown that a meta-learner could learn the direct rules to update learner parameters; and that the learnt neural optimiser updated learners more rapidly than handcrafted gradient-descent methods. However, we demonstrate that previous neural optimisers were limited to update learners on one designated dataset. In order to address input-domain heterogeneity, we introduce Multi-Task Learning to Learn (MTL2L), a context aware neural optimiser which self-modifies its optimisation rules based on input data. We show that MTL2L is capable of updating learners to classify on data of an unseen input-domain at the meta-testing phase.