 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnifying Multimodal Transformer for Bi-directional Image and Text Generation
Paper and Code
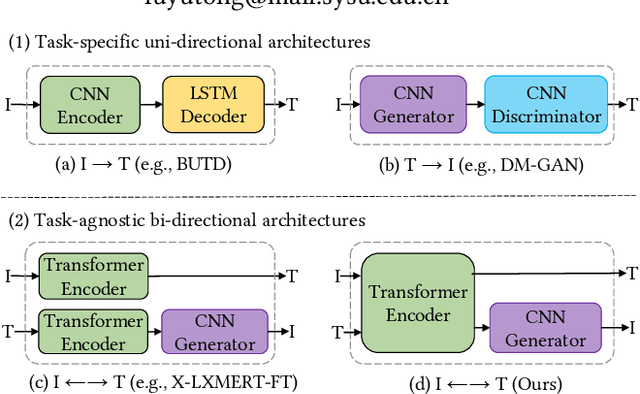
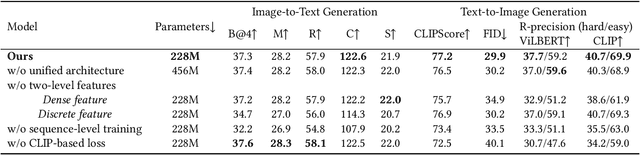
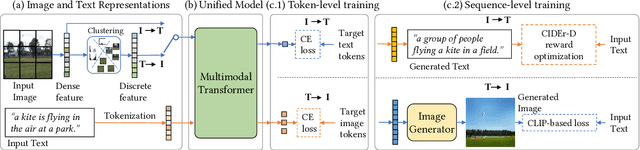
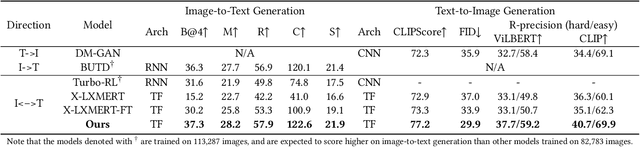
We study the joint learning of image-to-text and text-to-image generations, which are naturally bi-directional tasks. Typical existing works design two separate task-specific models for each task, which impose expensive design efforts. In this work, we propose a unified image-and-text generative framework based on a single multimodal model to jointly study the bi-directional tasks. We adopt Transformer as our unified architecture for its strong performance and task-agnostic design. Specifically, we formulate both tasks as sequence generation tasks, where we represent images and text as unified sequences of tokens, and the Transformer learns multimodal interactions to generate sequences. We further propose two-level granularity feature representations and sequence-level training to improve the Transformer-based unified framework. Experiments show that our approach significantly improves previous Transformer-based model X-LXMERT's FID from 37.0 to 29.9 (lower is better) for text-to-image generation, and improves CIDEr-D score from 100.9% to 122.6% for fine-tuned image-to-text generation on the MS-COCO dataset. Our code is available online.