 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZJUKLAB at SemEval-2021 Task 4: Negative Augmentation with Language Model for Reading Comprehension of Abstract Meaning
Paper and Code

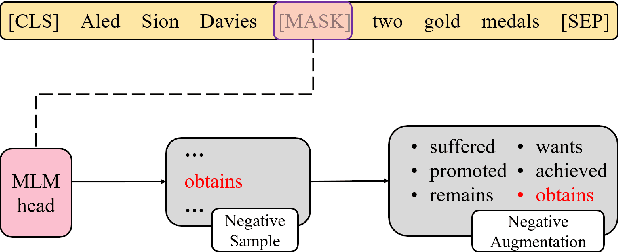

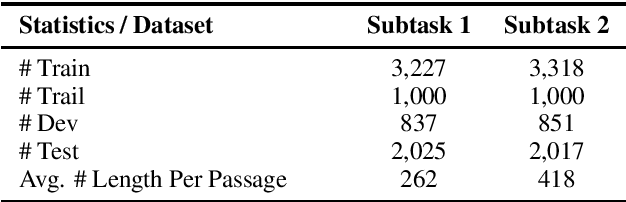
This paper presents our systems for the three Subtasks of SemEval Task4: Reading Comprehension of Abstract Meaning (ReCAM). We explain the algorithms used to learn our models and the process of tuning the algorithms and selecting the best model. Inspired by the similarity of the ReCAM task and the language pre-training, we propose a simple yet effective technology, namely, negative augmentation with language model. Evaluation results demonstrate the effectiveness of our proposed approach. Our models achieve the 4th rank on both official test sets of Subtask 1 and Subtask 2 with an accuracy of 87.9% and an accuracy of 92.8%, respectively. We further conduct comprehensive model analysis and observe interesting error cases, which may promote future researches.