 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContrastive Instruction-Trajectory Learning for Vision-Language Navigation
Paper and Code
Dec 09, 2021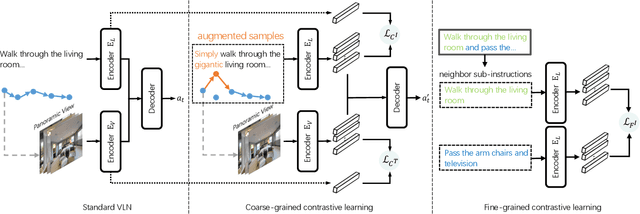
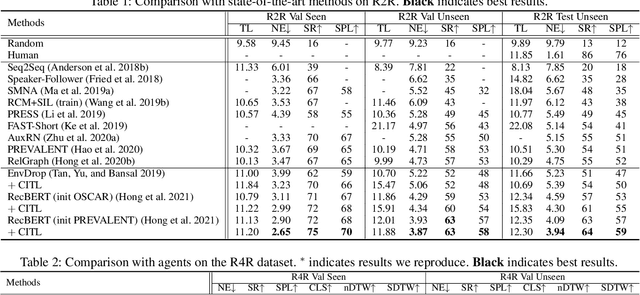
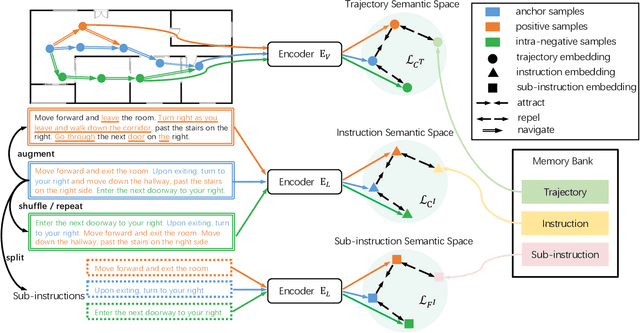
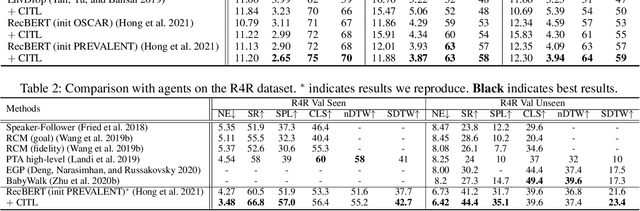
The vision-language navigation (VLN) task requires an agent to reach a target with the guidance of natural language instruction. Previous works learn to navigate step-by-step following an instruction. However, these works may fail to discriminate the similarities and discrepancies across instruction-trajectory pairs and ignore the temporal continuity of sub-instructions. These problems hinder agents from learning distinctive vision-and-language representations, harming the robustness and generalizability of the navigation policy. In this paper, we propose a Contrastive Instruction-Trajectory Learning (CITL) framework that explores invariance across similar data samples and variance across different ones to learn distinctive representations for robust navigation. Specifically, we propose: (1) a coarse-grained contrastive learning objective to enhance vision-and-language representations by contrasting semantics of full trajectory observations and instructions, respectively; (2) a fine-grained contrastive learning objective to perceive instructions by leveraging the temporal information of the sub-instructions; (3) a pairwise sample-reweighting mechanism for contrastive learning to mine hard samples and hence mitigate the influence of data sampling bias in contrastive learning. Our CITL can be easily integrated with VLN backbones to form a new learning paradigm and achieve better generalizability in unseen environments. Extensive experiments show that the model with CITL surpasses the previous state-of-the-art methods on R2R, R4R, and RxR.