 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmniKnight: Multilingual Neural Machine Translation with Language-Specific Self-Distillation
Paper and Code
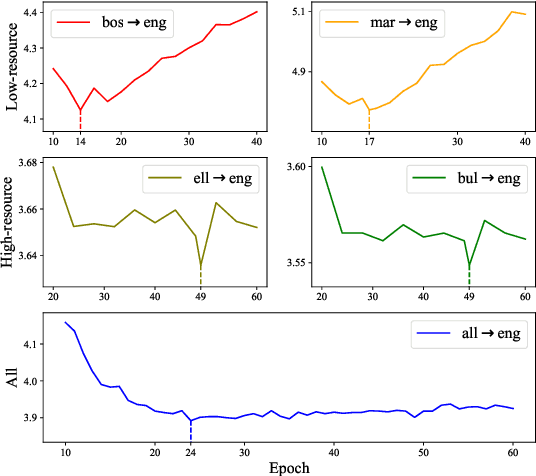
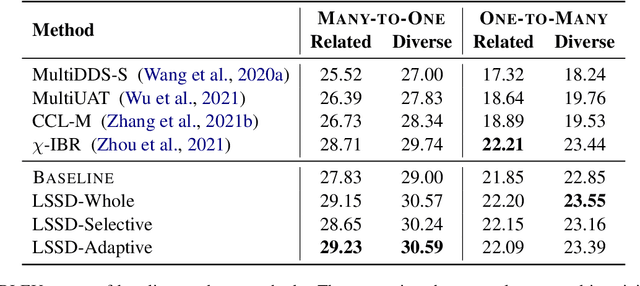
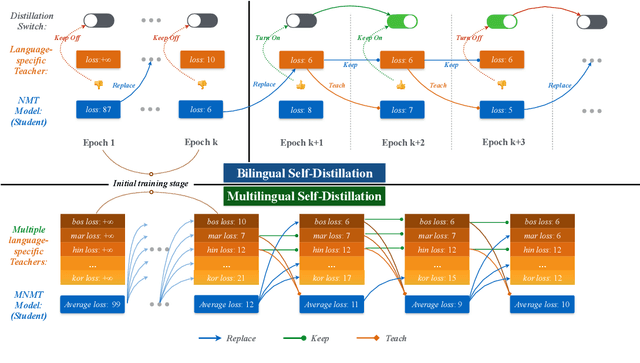
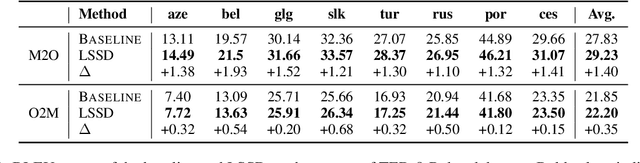
Although all-in-one-model multilingual neural machine translation (MNMT) has achieved remarkable progress in recent years, its selected best overall checkpoint fails to achieve the best performance simultaneously in all language pairs. It is because that the best checkpoints for each individual language pair (i.e., language-specific best checkpoints) scatter in different epochs. In this paper, we present a novel training strategy dubbed Language-Specific Self-Distillation (LSSD) for bridging the gap between language-specific best checkpoints and the overall best checkpoint. In detail, we regard each language-specific best checkpoint as a teacher to distill the overall best checkpoint. Moreover, we systematically explore three variants of our LSSD, which perform distillation statically, selectively, and adaptively. Experimental results on two widely-used benchmarks show that LSSD obtains consistent improvements towards all language pairs and achieves the state-of-the-art