 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring and Adapting Chinese GPT to Pinyin Input Method
Paper and Code

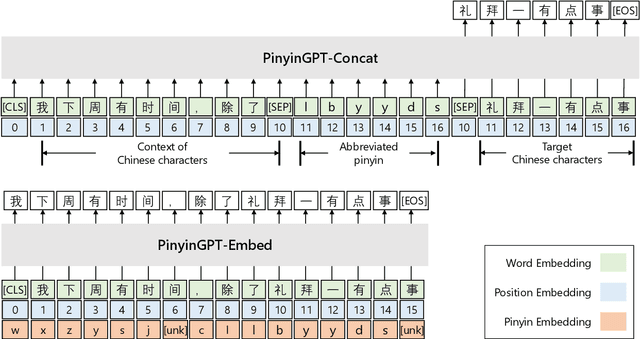

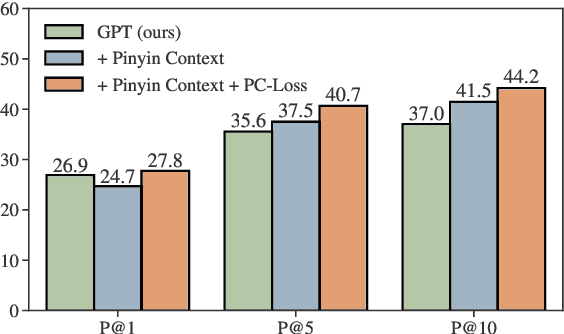
While GPT has become the de-facto method for text generation tasks, its application to pinyin input method remains unexplored. In this work, we make the first exploration to leverage Chinese GPT for pinyin input method. We find that a frozen GPT achieves state-of-the-art performance on perfect pinyin. However, the performance drops dramatically when the input includes abbreviated pinyin. A reason is that an abbreviated pinyin can be mapped to many perfect pinyin, which links to even larger number of Chinese characters. We mitigate this issue with two strategies, including enriching the context with pinyin and optimizing the training process to help distinguish homophones. To further facilitate the evaluation of pinyin input method, we create a dataset consisting of 270K instances from 15 domains. Results show that our approach improves performance on abbreviated pinyin across all domains. Model analysis demonstrates that both strategies contribute to the performance boost.