 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoaw: Unleashing Motion Awareness for Video Diffusion Models
Jan 19, 2026Video diffusion models, trained on large-scale datasets, naturally capture correspondences of shared features across frames. Recent works have exploited this property for tasks such as optical flow prediction and tracking in a zero-shot setting. Motivated by these findings, we investigate whether supervised training can more fully harness the tracking capability of video diffusion models. To this end, we propose Moaw, a framework that unleashes motion awareness for video diffusion models and leverages it to facilitate motion transfer. Specifically, we train a diffusion model for motion perception, shifting its modality from image-to-video generation to video-to-dense-tracking. We then construct a motion-labeled dataset to identify features that encode the strongest motion information, and inject them into a structurally identical video generation model. Owing to the homogeneity between the two networks, these features can be naturally adapted in a zero-shot manner, enabling motion transfer without additional adapters. Our work provides a new paradigm for bridging generative modeling and motion understanding, paving the way for more unified and controllable video learning frameworks.
Terra: Explorable Native 3D World Model with Point Latents
Oct 16, 2025World models have garnered increasing attention for comprehensive modeling of the real world. However, most existing methods still rely on pixel-aligned representations as the basis for world evolution, neglecting the inherent 3D nature of the physical world. This could undermine the 3D consistency and diminish the modeling efficiency of world models. In this paper, we present Terra, a native 3D world model that represents and generates explorable environments in an intrinsic 3D latent space. Specifically, we propose a novel point-to-Gaussian variational autoencoder (P2G-VAE) that encodes 3D inputs into a latent point representation, which is subsequently decoded as 3D Gaussian primitives to jointly model geometry and appearance. We then introduce a sparse point flow matching network (SPFlow) for generating the latent point representation, which simultaneously denoises the positions and features of the point latents. Our Terra enables exact multi-view consistency with native 3D representation and architecture, and supports flexible rendering from any viewpoint with only a single generation process. Furthermore, Terra achieves explorable world modeling through progressive generation in the point latent space. We conduct extensive experiments on the challenging indoor scenes from ScanNet v2. Terra achieves state-of-the-art performance in both reconstruction and generation with high 3D consistency.
SpectralAR: Spectral Autoregressive Visual Generation
Jun 12, 2025Autoregressive visual generation has garnered increasing attention due to its scalability and compatibility with other modalities compared with diffusion models. Most existing methods construct visual sequences as spatial patches for autoregressive generation. However, image patches are inherently parallel, contradicting the causal nature of autoregressive modeling. To address this, we propose a Spectral AutoRegressive (SpectralAR) visual generation framework, which realizes causality for visual sequences from the spectral perspective. Specifically, we first transform an image into ordered spectral tokens with Nested Spectral Tokenization, representing lower to higher frequency components. We then perform autoregressive generation in a coarse-to-fine manner with the sequences of spectral tokens. By considering different levels of detail in images, our SpectralAR achieves both sequence causality and token efficiency without bells and whistles. We conduct extensive experiments on ImageNet-1K for image reconstruction and autoregressive generation, and SpectralAR achieves 3.02 gFID with only 64 tokens and 310M parameters. Project page: https://huang-yh.github.io/spectralar/.
SceneCompleter: Dense 3D Scene Completion for Generative Novel View Synthesis
Jun 12, 2025Generative models have gained significant attention in novel view synthesis (NVS) by alleviating the reliance on dense multi-view captures. However, existing methods typically fall into a conventional paradigm, where generative models first complete missing areas in 2D, followed by 3D recovery techniques to reconstruct the scene, which often results in overly smooth surfaces and distorted geometry, as generative models struggle to infer 3D structure solely from RGB data. In this paper, we propose SceneCompleter, a novel framework that achieves 3D-consistent generative novel view synthesis through dense 3D scene completion. SceneCompleter achieves both visual coherence and 3D-consistent generative scene completion through two key components: (1) a geometry-appearance dual-stream diffusion model that jointly synthesizes novel views in RGBD space; (2) a scene embedder that encodes a more holistic scene understanding from the reference image. By effectively fusing structural and textural information, our method demonstrates superior coherence and plausibility in generative novel view synthesis across diverse datasets. Project Page: https://chen-wl20.github.io/SceneCompleter
GaussianWorld: Gaussian World Model for Streaming 3D Occupancy Prediction
Dec 13, 2024


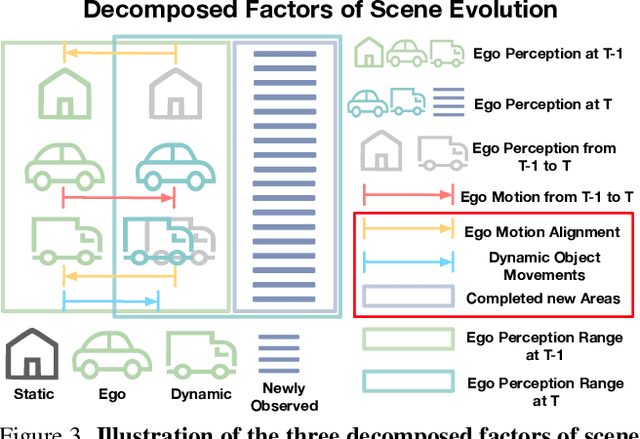
3D occupancy prediction is important for autonomous driving due to its comprehensive perception of the surroundings. To incorporate sequential inputs, most existing methods fuse representations from previous frames to infer the current 3D occupancy. However, they fail to consider the continuity of driving scenarios and ignore the strong prior provided by the evolution of 3D scenes (e.g., only dynamic objects move). In this paper, we propose a world-model-based framework to exploit the scene evolution for perception. We reformulate 3D occupancy prediction as a 4D occupancy forecasting problem conditioned on the current sensor input. We decompose the scene evolution into three factors: 1) ego motion alignment of static scenes; 2) local movements of dynamic objects; and 3) completion of newly-observed scenes. We then employ a Gaussian world model (GaussianWorld) to explicitly exploit these priors and infer the scene evolution in the 3D Gaussian space considering the current RGB observation. We evaluate the effectiveness of our framework on the widely used nuScenes dataset. Our GaussianWorld improves the performance of the single-frame counterpart by over 2% in mIoU without introducing additional computations. Code: https://github.com/zuosc19/GaussianWorld.
Doe-1: Closed-Loop Autonomous Driving with Large World Model
Dec 12, 2024End-to-end autonomous driving has received increasing attention due to its potential to learn from large amounts of data. However, most existing methods are still open-loop and suffer from weak scalability, lack of high-order interactions, and inefficient decision-making. In this paper, we explore a closed-loop framework for autonomous driving and propose a large Driving wOrld modEl (Doe-1) for unified perception, prediction, and planning. We formulate autonomous driving as a next-token generation problem and use multi-modal tokens to accomplish different tasks. Specifically, we use free-form texts (i.e., scene descriptions) for perception and generate future predictions directly in the RGB space with image tokens. For planning, we employ a position-aware tokenizer to effectively encode action into discrete tokens. We train a multi-modal transformer to autoregressively generate perception, prediction, and planning tokens in an end-to-end and unified manner. Experiments on the widely used nuScenes dataset demonstrate the effectiveness of Doe-1 in various tasks including visual question-answering, action-conditioned video generation, and motion planning. Code: https://github.com/wzzheng/Doe.
Owl-1: Omni World Model for Consistent Long Video Generation
Dec 12, 2024



Video generation models (VGMs) have received extensive attention recently and serve as promising candidates for general-purpose large vision models. While they can only generate short videos each time, existing methods achieve long video generation by iteratively calling the VGMs, using the last-frame output as the condition for the next-round generation. However, the last frame only contains short-term fine-grained information about the scene, resulting in inconsistency in the long horizon. To address this, we propose an Omni World modeL (Owl-1) to produce long-term coherent and comprehensive conditions for consistent long video generation. As videos are observations of the underlying evolving world, we propose to model the long-term developments in a latent space and use VGMs to film them into videos. Specifically, we represent the world with a latent state variable which can be decoded into explicit video observations. These observations serve as a basis for anticipating temporal dynamics which in turn update the state variable. The interaction between evolving dynamics and persistent state enhances the diversity and consistency of the long videos. Extensive experiments show that Owl-1 achieves comparable performance with SOTA methods on VBench-I2V and VBench-Long, validating its ability to generate high-quality video observations. Code: https://github.com/huang-yh/Owl.
GaussianFormer-2: Probabilistic Gaussian Superposition for Efficient 3D Occupancy Prediction
Dec 06, 2024



3D semantic occupancy prediction is an important task for robust vision-centric autonomous driving, which predicts fine-grained geometry and semantics of the surrounding scene. Most existing methods leverage dense grid-based scene representations, overlooking the spatial sparsity of the driving scenes. Although 3D semantic Gaussian serves as an object-centric sparse alternative, most of the Gaussians still describe the empty region with low efficiency. To address this, we propose a probabilistic Gaussian superposition model which interprets each Gaussian as a probability distribution of its neighborhood being occupied and conforms to probabilistic multiplication to derive the overall geometry. Furthermore, we adopt the exact Gaussian mixture model for semantics calculation to avoid unnecessary overlapping of Gaussians. To effectively initialize Gaussians in non-empty region, we design a distribution-based initialization module which learns the pixel-aligned occupancy distribution instead of the depth of surfaces. We conduct extensive experiments on nuScenes and KITTI-360 datasets and our GaussianFormer-2 achieves state-of-the-art performance with high efficiency. Code: https://github.com/huang-yh/GaussianFormer.
EmbodiedOcc: Embodied 3D Occupancy Prediction for Vision-based Online Scene Understanding
Dec 05, 2024
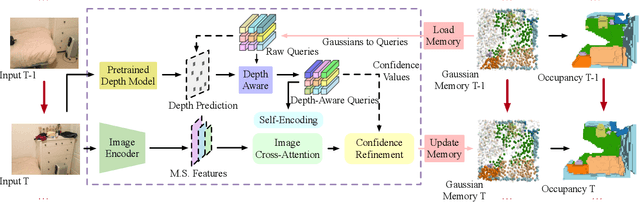


3D occupancy prediction provides a comprehensive description of the surrounding scenes and has become an essential task for 3D perception. Most existing methods focus on offline perception from one or a few views and cannot be applied to embodied agents which demands to gradually perceive the scene through progressive embodied exploration. In this paper, we formulate an embodied 3D occupancy prediction task to target this practical scenario and propose a Gaussian-based EmbodiedOcc framework to accomplish it. We initialize the global scene with uniform 3D semantic Gaussians and progressively update local regions observed by the embodied agent. For each update, we extract semantic and structural features from the observed image and efficiently incorporate them via deformable cross-attention to refine the regional Gaussians. Finally, we employ Gaussian-to-voxel splatting to obtain the global 3D occupancy from the updated 3D Gaussians. Our EmbodiedOcc assumes an unknown (i.e., uniformly distributed) environment and maintains an explicit global memory of it with 3D Gaussians. It gradually gains knowledge through local refinement of regional Gaussians, which is consistent with how humans understand new scenes through embodied exploration. We reorganize an EmbodiedOcc-ScanNet benchmark based on local annotations to facilitate the evaluation of the embodied 3D occupancy prediction task. Experiments demonstrate that our EmbodiedOcc outperforms existing local prediction methods and accomplishes the embodied occupancy prediction with high accuracy and strong expandability. Our code is available at: https://github.com/YkiWu/EmbodiedOcc.
Probabilistic Gaussian Superposition for Efficient 3D Occupancy Prediction
Dec 05, 20243D semantic occupancy prediction is an important task for robust vision-centric autonomous driving, which predicts fine-grained geometry and semantics of the surrounding scene. Most existing methods leverage dense grid-based scene representations, overlooking the spatial sparsity of the driving scenes. Although 3D semantic Gaussian serves as an object-centric sparse alternative, most of the Gaussians still describe the empty region with low efficiency. To address this, we propose a probabilistic Gaussian superposition model which interprets each Gaussian as a probability distribution of its neighborhood being occupied and conforms to probabilistic multiplication to derive the overall geometry. Furthermore, we adopt the exact Gaussian mixture model for semantics calculation to avoid unnecessary overlapping of Gaussians. To effectively initialize Gaussians in non-empty region, we design a distribution-based initialization module which learns the pixel-aligned occupancy distribution instead of the depth of surfaces. We conduct extensive experiments on nuScenes and KITTI-360 datasets and our GaussianFormer-2 achieves state-of-the-art performance with high efficiency. Code: https://github.com/huang-yh/GaussianFormer.