 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHFT: Lifting Perspective Representations via Hybrid Feature Transformation
Paper and Code


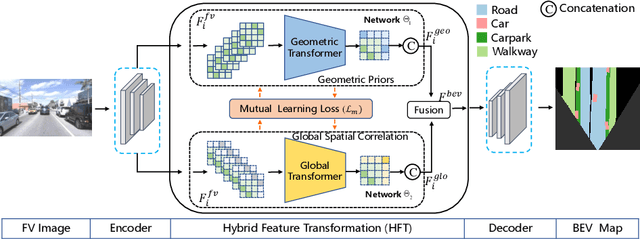
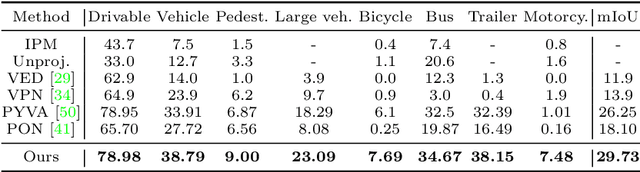
Autonomous driving requires accurate and detailed Bird's Eye View (BEV) semantic segmentation for decision making, which is one of the most challenging tasks for high-level scene perception. Feature transformation from frontal view to BEV is the pivotal technology for BEV semantic segmentation. Existing works can be roughly classified into two categories, i.e., Camera model-Based Feature Transformation (CBFT) and Camera model-Free Feature Transformation (CFFT). In this paper, we empirically analyze the vital differences between CBFT and CFFT. The former transforms features based on the flat-world assumption, which may cause distortion of regions lying above the ground plane. The latter is limited in the segmentation performance due to the absence of geometric priors and time-consuming computation. In order to reap the benefits and avoid the drawbacks of CBFT and CFFT, we propose a novel framework with a Hybrid Feature Transformation module (HFT). Specifically, we decouple the feature maps produced by HFT for estimating the layout of outdoor scenes in BEV. Furthermore, we design a mutual learning scheme to augment hybrid transformation by applying feature mimicking. Notably, extensive experiments demonstrate that with negligible extra overhead, HFT achieves a relative improvement of 13.3% on the Argoverse dataset and 16.8% on the KITTI 3D Object datasets compared to the best-performing existing method. The codes are available at https://github.com/JiayuZou2020/HFT.