 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePSAQ-ViT V2: Towards Accurate and General Data-Free Quantization for Vision Transformers
Paper and Code
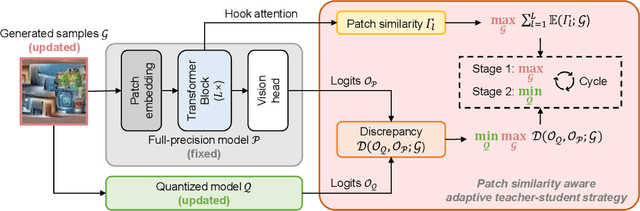
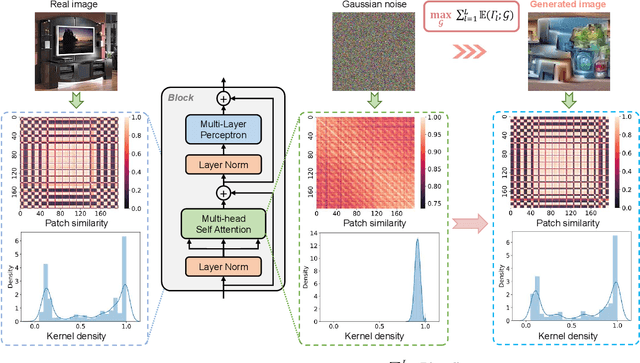


Data-free quantization can potentially address data privacy and security concerns in model compression, and thus has been widely investigated. Recently, PSAQ-ViT designs a relative value metric, patch similarity, to generate data from pre-trained vision transformers (ViTs), achieving the first attempt at data-free quantization for ViTs. In this paper, we propose PSAQ-ViT V2, a more accurate and general data-free quantization framework for ViTs, built on top of PSAQ-ViT. More specifically, following the patch similarity metric in PSAQ-ViT, we introduce an adaptive teacher-student strategy, which facilitates the constant cyclic evolution of the generated samples and the quantized model (student) in a competitive and interactive fashion under the supervision of the full-precision model (teacher), thus significantly improving the accuracy of the quantized model. Moreover, without the auxiliary category guidance, we employ the task- and model-independent prior information, making the general-purpose scheme compatible with a broad range of vision tasks and models. Extensive experiments are conducted on various models on image classification, object detection, and semantic segmentation tasks, and PSAQ-ViT V2, with the naive quantization strategy and without access to real-world data, consistently achieves competitive results, showing potential as a powerful baseline on data-free quantization for ViTs. For instance, with Swin-S as the (backbone) model, 8-bit quantization reaches 82.13 top-1 accuracy on ImageNet, 50.9 box AP and 44.1 mask AP on COCO, and 47.2 mIoU on ADE20K. We hope that accurate and general PSAQ-ViT V2 can serve as a potential and practice solution in real-world applications involving sensitive data. Code will be released and merged at: https://github.com/zkkli/PSAQ-ViT.