 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePTQ4ARVG: Post-Training Quantization for AutoRegressive Visual Generation Models
Jan 29, 2026AutoRegressive Visual Generation (ARVG) models retain an architecture compatible with language models, while achieving performance comparable to diffusion-based models. Quantization is commonly employed in neural networks to reduce model size and computational latency. However, applying quantization to ARVG remains largely underexplored, and existing quantization methods fail to generalize effectively to ARVG models. In this paper, we explore this issue and identify three key challenges: (1) severe outliers at channel-wise level, (2) highly dynamic activations at token-wise level, and (3) mismatched distribution information at sample-wise level. To these ends, we propose PTQ4ARVG, a training-free post-training quantization (PTQ) framework consisting of: (1) Gain-Projected Scaling (GPS) mitigates the channel-wise outliers, which expands the quantization loss via a Taylor series to quantify the gain of scaling for activation-weight quantization, and derives the optimal scaling factor through differentiation.(2) Static Token-Wise Quantization (STWQ) leverages the inherent properties of ARVG, fixed token length and position-invariant distribution across samples, to address token-wise variance without incurring dynamic calibration overhead.(3) Distribution-Guided Calibration (DGC) selects samples that contribute most to distributional entropy, eliminating the sample-wise distribution mismatch. Extensive experiments show that PTQ4ARVG can effectively quantize the ARVG family models to 8-bit and 6-bit while maintaining competitive performance. Code is available at http://github.com/BienLuky/PTQ4ARVG .
CacheQuant: Comprehensively Accelerated Diffusion Models
Mar 03, 2025Diffusion models have gradually gained prominence in the field of image synthesis, showcasing remarkable generative capabilities. Nevertheless, the slow inference and complex networks, resulting from redundancy at both temporal and structural levels, hinder their low-latency applications in real-world scenarios. Current acceleration methods for diffusion models focus separately on temporal and structural levels. However, independent optimization at each level to further push the acceleration limits results in significant performance degradation. On the other hand, integrating optimizations at both levels can compound the acceleration effects. Unfortunately, we find that the optimizations at these two levels are not entirely orthogonal. Performing separate optimizations and then simply integrating them results in unsatisfactory performance. To tackle this issue, we propose CacheQuant, a novel training-free paradigm that comprehensively accelerates diffusion models by jointly optimizing model caching and quantization techniques. Specifically, we employ a dynamic programming approach to determine the optimal cache schedule, in which the properties of caching and quantization are carefully considered to minimize errors. Additionally, we propose decoupled error correction to further mitigate the coupled and accumulated errors step by step. Experimental results show that CacheQuant achieves a 5.18 speedup and 4 compression for Stable Diffusion on MS-COCO, with only a 0.02 loss in CLIP score. Our code are open-sourced: https://github.com/BienLuky/CacheQuant .
DilateQuant: Accurate and Efficient Diffusion Quantization via Weight Dilation
Sep 25, 2024



Diffusion models have shown excellent performance on various image generation tasks, but the substantial computational costs and huge memory footprint hinder their low-latency applications in real-world scenarios. Quantization is a promising way to compress and accelerate models. Nevertheless, due to the wide range and time-varying activations in diffusion models, existing methods cannot maintain both accuracy and efficiency simultaneously for low-bit quantization. To tackle this issue, we propose DilateQuant, a novel quantization framework for diffusion models that offers comparable accuracy and high efficiency. Specifically, we keenly aware of numerous unsaturated in-channel weights, which can be cleverly exploited to reduce the range of activations without additional computation cost. Based on this insight, we propose Weight Dilation (WD) that maximally dilates the unsaturated in-channel weights to a constrained range through a mathematically equivalent scaling. WD costlessly absorbs the activation quantization errors into weight quantization. The range of activations decreases, which makes activations quantization easy. The range of weights remains constant, which makes model easy to converge in training stage. Considering the temporal network leads to time-varying activations, we design a Temporal Parallel Quantizer (TPQ), which sets time-step quantization parameters and supports parallel quantization for different time steps, significantly improving the performance and reducing time cost. To further enhance performance while preserving efficiency, we introduce a Block-wise Knowledge Distillation (BKD) to align the quantized models with the full-precision models at a block level. The simultaneous training of time-step quantization parameters and weights minimizes the time required, and the shorter backpropagation paths decreases the memory footprint of the quantization process.
K-Sort Arena: Efficient and Reliable Benchmarking for Generative Models via K-wise Human Preferences
Aug 26, 2024



The rapid advancement of visual generative models necessitates efficient and reliable evaluation methods. Arena platform, which gathers user votes on model comparisons, can rank models with human preferences. However, traditional Arena methods, while established, require an excessive number of comparisons for ranking to converge and are vulnerable to preference noise in voting, suggesting the need for better approaches tailored to contemporary evaluation challenges. In this paper, we introduce K-Sort Arena, an efficient and reliable platform based on a key insight: images and videos possess higher perceptual intuitiveness than texts, enabling rapid evaluation of multiple samples simultaneously. Consequently, K-Sort Arena employs K-wise comparisons, allowing K models to engage in free-for-all competitions, which yield much richer information than pairwise comparisons. To enhance the robustness of the system, we leverage probabilistic modeling and Bayesian updating techniques. We propose an exploration-exploitation-based matchmaking strategy to facilitate more informative comparisons. In our experiments, K-Sort Arena exhibits 16.3x faster convergence compared to the widely used ELO algorithm. To further validate the superiority and obtain a comprehensive leaderboard, we collect human feedback via crowdsourced evaluations of numerous cutting-edge text-to-image and text-to-video models. Thanks to its high efficiency, K-Sort Arena can continuously incorporate emerging models and update the leaderboard with minimal votes. Our project has undergone several months of internal testing and is now available at https://huggingface.co/spaces/ksort/K-Sort-Arena
RepQuant: Towards Accurate Post-Training Quantization of Large Transformer Models via Scale Reparameterization
Feb 08, 2024



Large transformer models have demonstrated remarkable success. Post-training quantization (PTQ), which requires only a small dataset for calibration and avoids end-to-end retraining, is a promising solution for compressing these large models. Regrettably, existing PTQ methods typically exhibit non-trivial performance loss. We find that the performance bottleneck stems from over-consideration of hardware compatibility in the quantization process, compelling them to reluctantly employ simple quantizers, albeit at the expense of accuracy. With the above insights, we propose RepQuant, a novel PTQ framework with quantization-inference decoupling paradigm to address the above issues. RepQuant employs complex quantizers in the quantization process and simplified quantizers in the inference process, and performs mathematically equivalent transformations between the two through quantization scale reparameterization, thus ensuring both accurate quantization and efficient inference. More specifically, we focus on two components with extreme distributions: LayerNorm activations and Softmax activations. Initially, we apply channel-wise quantization and log$\sqrt{2}$ quantization, respectively, which are tailored to their distributions. In particular, for the former, we introduce a learnable per-channel dual clipping scheme, which is designed to efficiently identify outliers in the unbalanced activations with fine granularity. Then, we reparameterize the scales to hardware-friendly layer-wise quantization and log2 quantization for inference. Moreover, quantized weight reconstruction is seamlessly integrated into the above procedure to further push the performance limits. Extensive experiments are performed on different large-scale transformer variants on multiple tasks, including vision, language, and multi-modal transformers, and RepQuant encouragingly demonstrates significant performance advantages.
Enhanced Distribution Alignment for Post-Training Quantization of Diffusion Models
Jan 09, 2024
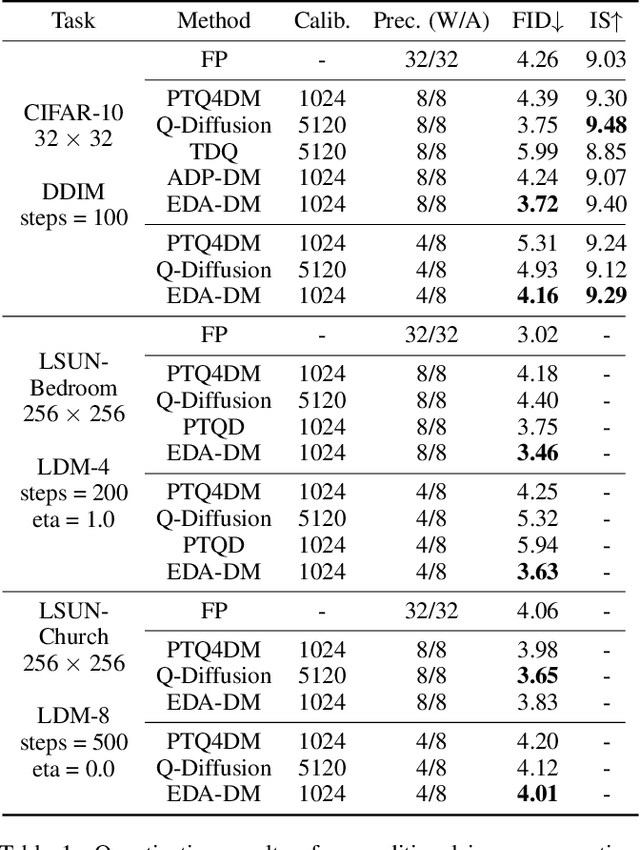


Diffusion models have achieved great success in image generation tasks through iterative noise estimation. However, the heavy denoising process and complex neural networks hinder their low-latency applications in real-world scenarios. Quantization can effectively reduce model complexity, and post-training quantization (PTQ), which does not require fine-tuning, is highly promising in accelerating the denoising process. Unfortunately, we find that due to the highly dynamic distribution of activations in different denoising steps, existing PTQ methods for diffusion models suffer from distribution mismatch issues at both calibration sample level and reconstruction output level, which makes the performance far from satisfactory, especially in low-bit cases. In this paper, we propose Enhanced Distribution Alignment for Post-Training Quantization of Diffusion Models (EDA-DM) to address the above issues. Specifically, at the calibration sample level, we select calibration samples based on the density and diversity in the latent space, thus facilitating the alignment of their distribution with the overall samples; and at the reconstruction output level, we propose Fine-grained Block Reconstruction, which can align the outputs of the quantized model and the full-precision model at different network granularity. Extensive experiments demonstrate that EDA-DM outperforms the existing post-training quantization frameworks in both unconditional and conditional generation scenarios. At low-bit precision, the quantized models with our method even outperform the full-precision models on most datasets.