 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAIM: Software and Hardware Co-design for Architecture-level IR-drop Mitigation in High-performance PIM
Nov 06, 2025



SRAM Processing-in-Memory (PIM) has emerged as the most promising implementation for high-performance PIM, delivering superior computing density, energy efficiency, and computational precision. However, the pursuit of higher performance necessitates more complex circuit designs and increased operating frequencies, which exacerbate IR-drop issues. Severe IR-drop can significantly degrade chip performance and even threaten reliability. Conventional circuit-level IR-drop mitigation methods, such as back-end optimizations, are resource-intensive and often compromise power, performance, and area (PPA). To address these challenges, we propose AIM, comprehensive software and hardware co-design for architecture-level IR-drop mitigation in high-performance PIM. Initially, leveraging the bit-serial and in-situ dataflow processing properties of PIM, we introduce Rtog and HR, which establish a direct correlation between PIM workloads and IR-drop. Building on this foundation, we propose LHR and WDS, enabling extensive exploration of architecture-level IR-drop mitigation while maintaining computational accuracy through software optimization. Subsequently, we develop IR-Booster, a dynamic adjustment mechanism that integrates software-level HR information with hardware-based IR-drop monitoring to adapt the V-f pairs of the PIM macro, achieving enhanced energy efficiency and performance. Finally, we propose the HR-aware task mapping method, bridging software and hardware designs to achieve optimal improvement. Post-layout simulation results on a 7nm 256-TOPS PIM chip demonstrate that AIM achieves up to 69.2% IR-drop mitigation, resulting in 2.29x energy efficiency improvement and 1.152x speedup.
PTQ-SL: Exploring the Sub-layerwise Post-training Quantization
Oct 18, 2021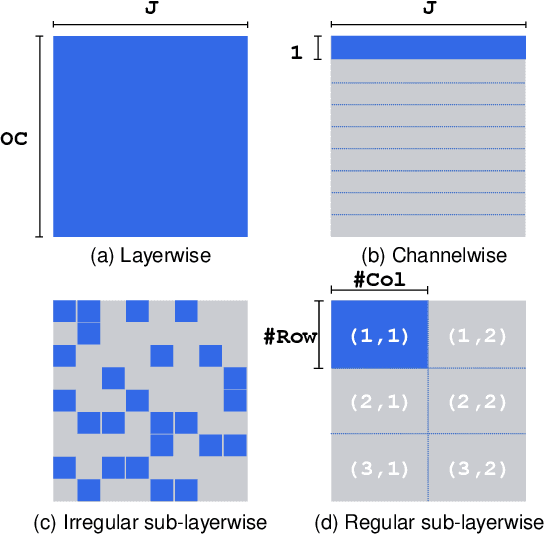
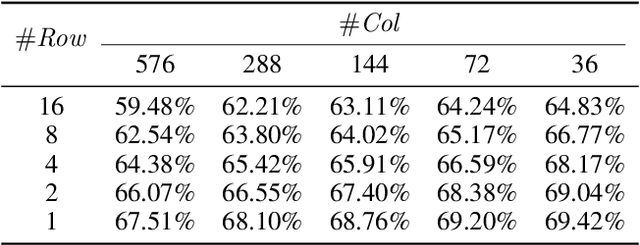
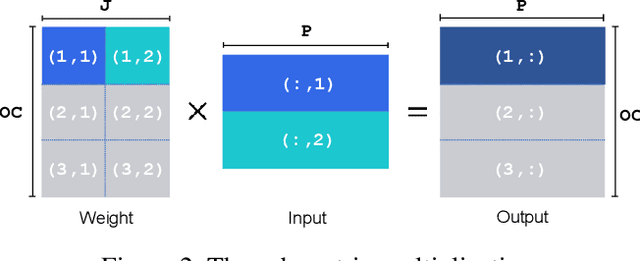
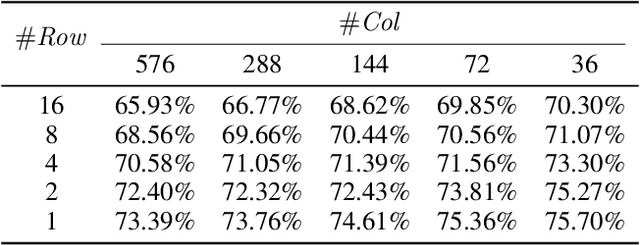
Network quantization is a powerful technique to compress convolutional neural networks. The quantization granularity determines how to share the scaling factors in weights, which affects the performance of network quantization. Most existing approaches share the scaling factors layerwisely or channelwisely for quantization of convolutional layers. Channelwise quantization and layerwise quantization have been widely used in various applications. However, other quantization granularities are rarely explored. In this paper, we will explore the sub-layerwise granularity that shares the scaling factor across multiple input and output channels. We propose an efficient post-training quantization method in sub-layerwise granularity (PTQ-SL). Then we systematically experiment on various granularities and observe that the prediction accuracy of the quantized neural network has a strong correlation with the granularity. Moreover, we find that adjusting the position of the channels can improve the performance of sub-layerwise quantization. Therefore, we propose a method to reorder the channels for sub-layerwise quantization. The experiments demonstrate that the sub-layerwise quantization with appropriate channel reordering can outperform the channelwise quantization.
End-to-End Human Object Interaction Detection with HOI Transformer
Mar 08, 2021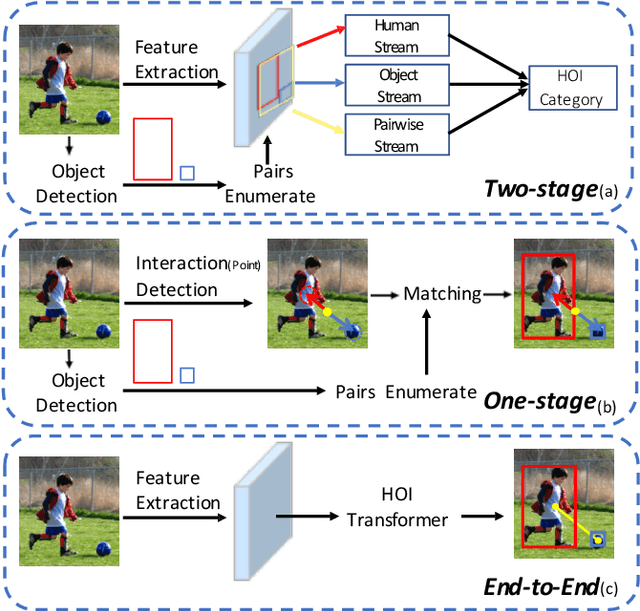
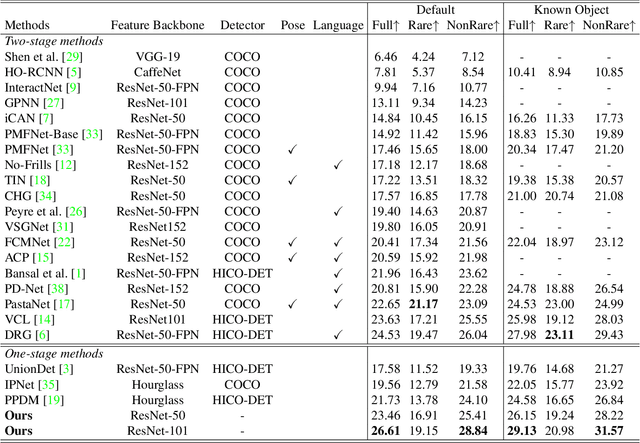
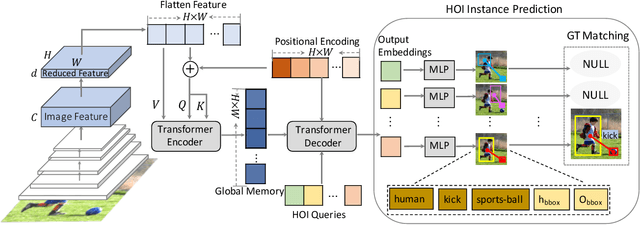

We propose HOI Transformer to tackle human object interaction (HOI) detection in an end-to-end manner. Current approaches either decouple HOI task into separated stages of object detection and interaction classification or introduce surrogate interaction problem. In contrast, our method, named HOI Transformer, streamlines the HOI pipeline by eliminating the need for many hand-designed components. HOI Transformer reasons about the relations of objects and humans from global image context and directly predicts HOI instances in parallel. A quintuple matching loss is introduced to force HOI predictions in a unified way. Our method is conceptually much simpler and demonstrates improved accuracy. Without bells and whistles, HOI Transformer achieves $26.61\% $ $ AP $ on HICO-DET and $52.9\%$ $AP_{role}$ on V-COCO, surpassing previous methods with the advantage of being much simpler. We hope our approach will serve as a simple and effective alternative for HOI tasks. Code is available at https://github.com/bbepoch/HoiTransformer .
Redundancy of Hidden Layers in Deep Learning: An Information Perspective
Sep 19, 2020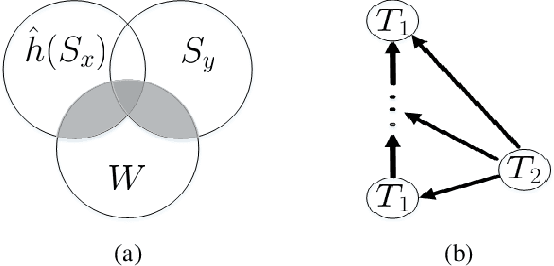
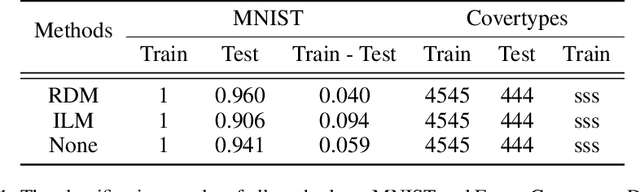
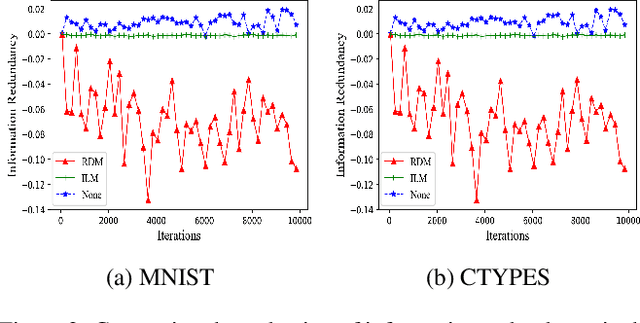
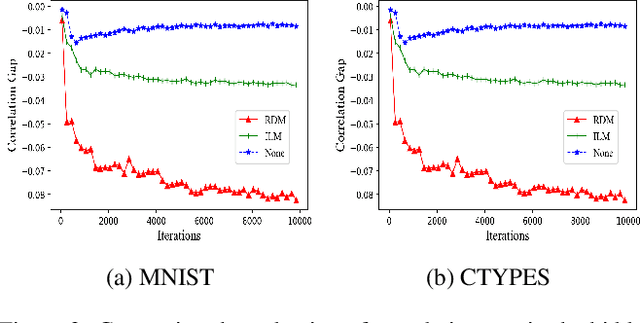
Although the deep structure guarantees the powerful expressivity of deep networks (DNNs), it also triggers serious overfitting problem. To improve the generalization capacity of DNNs, many strategies were developed to improve the diversity among hidden units. However, most of these strategies are empirical and heuristic in absence of either a theoretical derivation of the diversity measure or a clear connection from the diversity to the generalization capacity. In this paper, from an information theoretic perspective, we introduce a new definition of redundancy to describe the diversity of hidden units under supervised learning settings by formalizing the effect of hidden layers on the generalization capacity as the mutual information. We prove an opposite relationship existing between the defined redundancy and the generalization capacity, i.e., the decrease of redundancy generally improving the generalization capacity. The experiments show that the DNNs using the redundancy as the regularizer can effectively reduce the overfitting and decrease the generalization error, which well supports above points.