 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbabilistic Querying of Continuous-Time Event Sequences
Paper and Code
Nov 15, 2022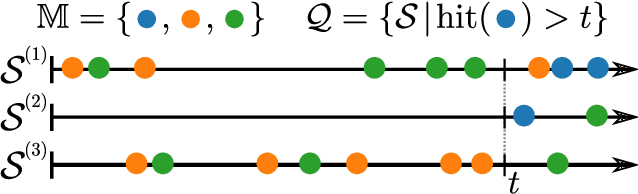

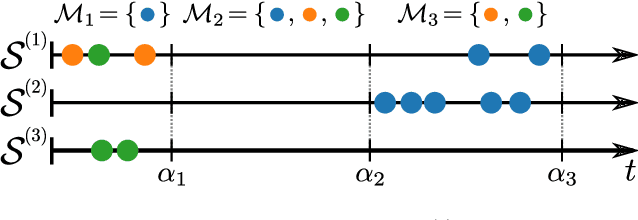
Continuous-time event sequences, i.e., sequences consisting of continuous time stamps and associated event types ("marks"), are an important type of sequential data with many applications, e.g., in clinical medicine or user behavior modeling. Since these data are typically modeled autoregressively (e.g., using neural Hawkes processes or their classical counterparts), it is natural to ask questions about future scenarios such as "what kind of event will occur next" or "will an event of type $A$ occur before one of type $B$". Unfortunately, some of these queries are notoriously hard to address since current methods are limited to naive simulation, which can be highly inefficient. This paper introduces a new typology of query types and a framework for addressing them using importance sampling. Example queries include predicting the $n^\text{th}$ event type in a sequence and the hitting time distribution of one or more event types. We also leverage these findings further to be applicable for estimating general "$A$ before $B$" type of queries. We prove theoretically that our estimation method is effectively always better than naive simulation and show empirically based on three real-world datasets that it is on average 1,000 times more efficient than existing approaches.