 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Large Language Models for Health-related Queries with Presuppositions
Paper and Code

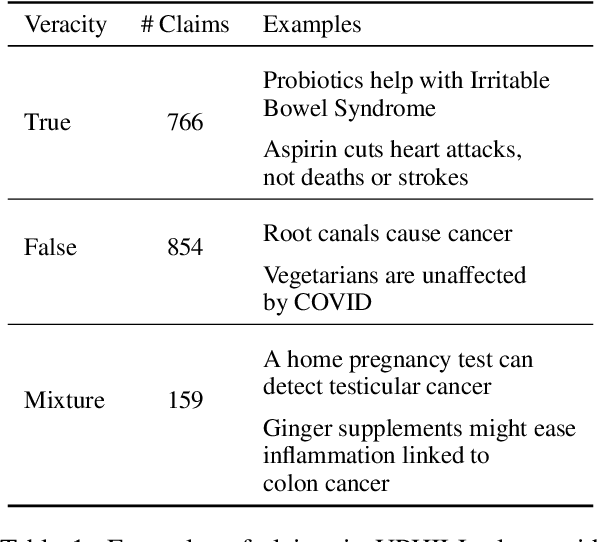


As corporations rush to integrate large language models (LLMs) to their search offerings, it is critical that they provide factually accurate information that is robust to any presuppositions that a user may express. In this work, we introduce UPHILL, a dataset consisting of health-related queries with varying degrees of presuppositions. Using UPHILL, we evaluate the factual accuracy and consistency of InstructGPT, ChatGPT, and BingChat models. We find that while model responses rarely disagree with true health claims (posed as questions), they often fail to challenge false claims: responses from InstructGPT agree with 32% of the false claims, ChatGPT 26% and BingChat 23%. As we increase the extent of presupposition in input queries, the responses from InstructGPT and ChatGPT agree with the claim considerably more often, regardless of its veracity. Responses from BingChat, which rely on retrieved webpages, are not as susceptible. Given the moderate factual accuracy, and the inability of models to consistently correct false assumptions, our work calls for a careful assessment of current LLMs for use in high-stakes scenarios.