 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA computational framework for longitudinal medication adherence prediction in breast cancer survivors: A social cognitive theory based approach
Apr 20, 2025
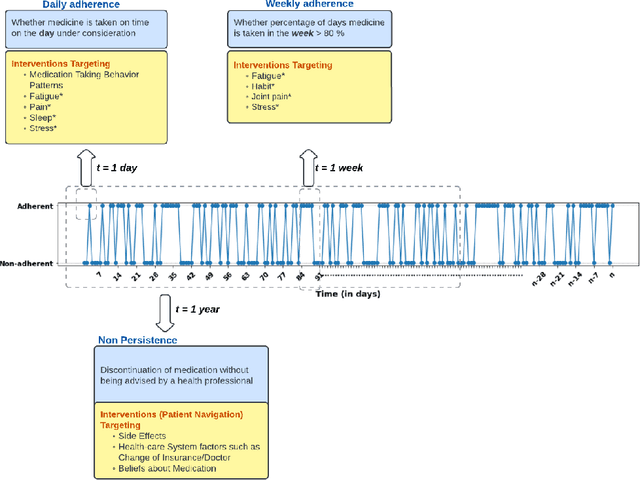


Non-adherence to medications is a critical concern since nearly half of patients with chronic illnesses do not follow their prescribed medication regimens, leading to increased mortality, costs, and preventable human distress. Amongst stage 0-3 breast cancer survivors, adherence to long-term adjuvant endocrine therapy (i.e., Tamoxifen and aromatase inhibitors) is associated with a significant increase in recurrence-free survival. This work aims to develop multi-scale models of medication adherence to understand the significance of different factors influencing adherence across varying time frames. We introduce a computational framework guided by Social Cognitive Theory for multi-scale (daily and weekly) modeling of longitudinal medication adherence. Our models employ both dynamic medication-taking patterns in the recent past (dynamic factors) as well as less frequently changing factors (static factors) for adherence prediction. Additionally, we assess the significance of various factors in influencing adherence behavior across different time scales. Our models outperform traditional machine learning counterparts in both daily and weekly tasks in terms of both accuracy and specificity. Daily models achieved an accuracy of 87.25%, and weekly models, an accuracy of 76.04%. Notably, dynamic past medication-taking patterns prove most valuable for predicting daily adherence, while a combination of dynamic and static factors is significant for macro-level weekly adherence patterns.
Knowledge Graph Guided Evaluation of Abstention Techniques
Dec 10, 2024



To deploy language models safely, it is crucial that they abstain from responding to inappropriate requests. Several prior studies test the safety promises of models based on their effectiveness in blocking malicious requests. In this work, we focus on evaluating the underlying techniques that cause models to abstain. We create SELECT, a benchmark derived from a set of benign concepts (e.g., "rivers") from a knowledge graph. The nature of SELECT enables us to isolate the effects of abstention techniques from other safety training procedures, as well as evaluate their generalization and specificity. Using SELECT, we benchmark different abstention techniques over six open-weight and closed-source models. We find that the examined techniques indeed cause models to abstain with over $80\%$ abstention rates. However, these techniques are not as effective for descendants of the target concepts, with refusal rates declining by $19\%$. We also characterize the generalization-vs-specificity trade-offs for different techniques. Overall, no single technique is invariably better than the others. Our findings call for a careful evaluation of different aspects of abstention, and hopefully inform practitioners of various trade-offs involved.
Evaluating Large Language Models for Health-related Queries with Presuppositions
Dec 14, 2023
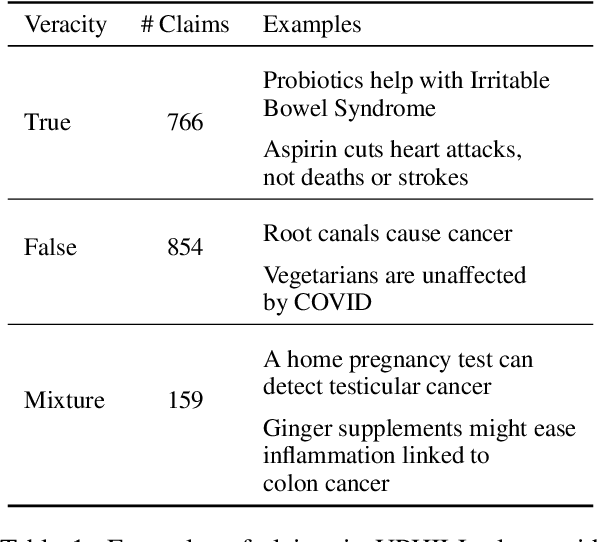


As corporations rush to integrate large language models (LLMs) to their search offerings, it is critical that they provide factually accurate information that is robust to any presuppositions that a user may express. In this work, we introduce UPHILL, a dataset consisting of health-related queries with varying degrees of presuppositions. Using UPHILL, we evaluate the factual accuracy and consistency of InstructGPT, ChatGPT, and BingChat models. We find that while model responses rarely disagree with true health claims (posed as questions), they often fail to challenge false claims: responses from InstructGPT agree with 32% of the false claims, ChatGPT 26% and BingChat 23%. As we increase the extent of presupposition in input queries, the responses from InstructGPT and ChatGPT agree with the claim considerably more often, regardless of its veracity. Responses from BingChat, which rely on retrieved webpages, are not as susceptible. Given the moderate factual accuracy, and the inability of models to consistently correct false assumptions, our work calls for a careful assessment of current LLMs for use in high-stakes scenarios.