 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFair Effect Attribution in Parallel Online Experiments
Oct 15, 2022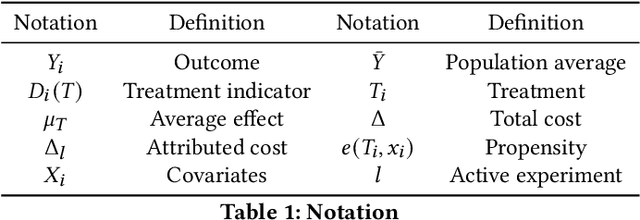

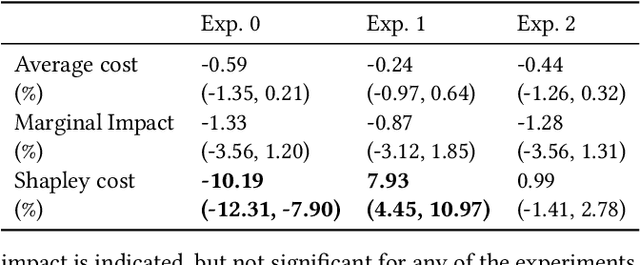
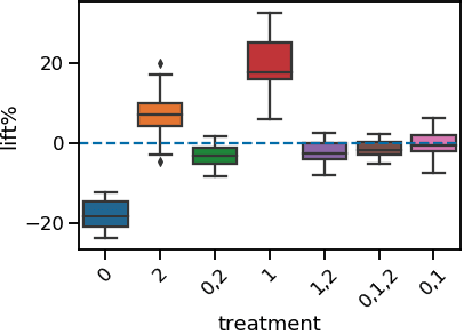
A/B tests serve the purpose of reliably identifying the effect of changes introduced in online services. It is common for online platforms to run a large number of simultaneous experiments by splitting incoming user traffic randomly in treatment and control groups. Despite a perfect randomization between different groups, simultaneous experiments can interact with each other and create a negative impact on average population outcomes such as engagement metrics. These are measured globally and monitored to protect overall user experience. Therefore, it is crucial to measure these interaction effects and attribute their overall impact in a fair way to the respective experimenters. We suggest an approach to measure and disentangle the effect of simultaneous experiments by providing a cost sharing approach based on Shapley values. We also provide a counterfactual perspective, that predicts shared impact based on conditional average treatment effects making use of causal inference techniques. We illustrate our approach in real world and synthetic data experiments.
* Published as https://dl.acm.org/doi/10.1145/3487553.3524211
Low-variance estimation in the Plackett-Luce model via quasi-Monte Carlo sampling
May 12, 2022
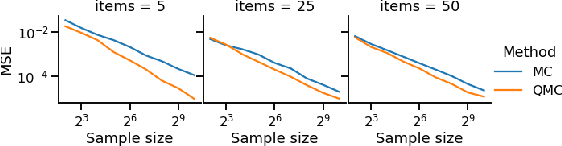
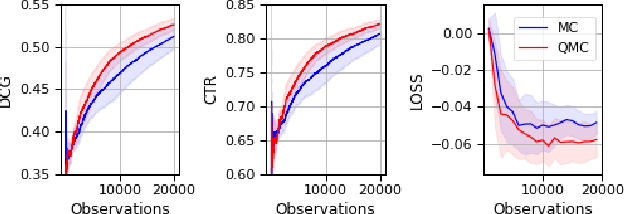

The Plackett-Luce (PL) model is ubiquitous in learning-to-rank (LTR) because it provides a useful and intuitive probabilistic model for sampling ranked lists. Counterfactual offline evaluation and optimization of ranking metrics are pivotal for using LTR methods in production. When adopting the PL model as a ranking policy, both tasks require the computation of expectations with respect to the model. These are usually approximated via Monte-Carlo (MC) sampling, since the combinatorial scaling in the number of items to be ranked makes their analytical computation intractable. Despite recent advances in improving the computational efficiency of the sampling process via the Gumbel top-k trick, the MC estimates can suffer from high variance. We develop a novel approach to producing more sample-efficient estimators of expectations in the PL model by combining the Gumbel top-k trick with quasi-Monte Carlo (QMC) sampling, a well-established technique for variance reduction. We illustrate our findings both theoretically and empirically using real-world recommendation data from Amazon Music and the Yahoo learning-to-rank challenge.
Ranker-agnostic Contextual Position Bias Estimation
Jul 28, 2021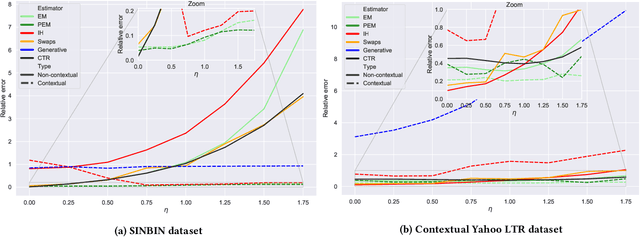

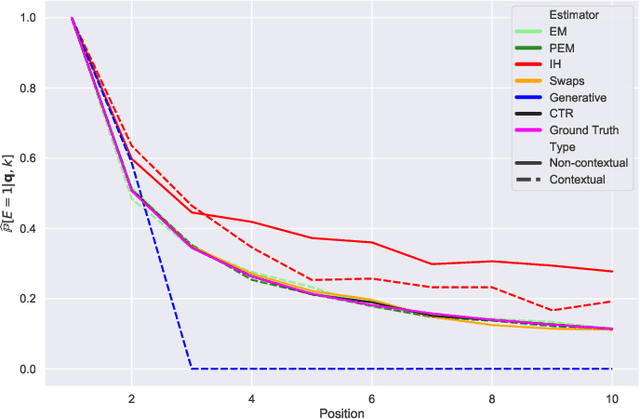

Learning-to-rank (LTR) algorithms are ubiquitous and necessary to explore the extensive catalogs of media providers. To avoid the user examining all the results, its preferences are used to provide a subset of relatively small size. The user preferences can be inferred from the interactions with the presented content if explicit ratings are unavailable. However, directly using implicit feedback can lead to learning wrong relevance models and is known as biased LTR. The mismatch between implicit feedback and true relevances is due to various nuisances, with position bias one of the most relevant. Position bias models consider that the lack of interaction with a presented item is not only attributed to the item being irrelevant but because the item was not examined. This paper introduces a method for modeling the probability of an item being seen in different contexts, e.g., for different users, with a single estimator. Our suggested method, denoted as contextual (EM)-based regression, is ranker-agnostic and able to correctly learn the latent examination probabilities while only using implicit feedback. Our empirical results indicate that the method introduced in this paper outperforms other existing position bias estimators in terms of relative error when the examination probability varies across queries. Moreover, the estimated values provide a ranking performance boost when used to debias the implicit ranking data even if there is no context dependency on the examination probabilities.
A Linear Bandit for Seasonal Environments
Apr 28, 2020
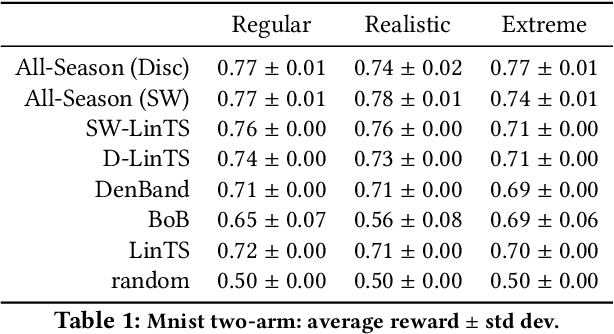
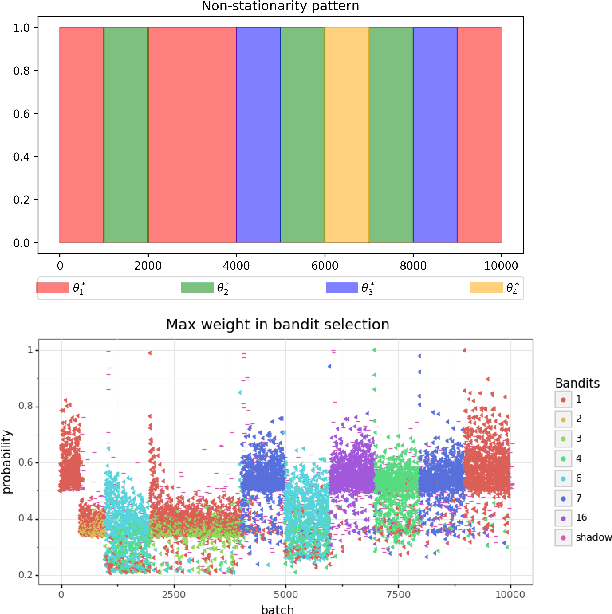
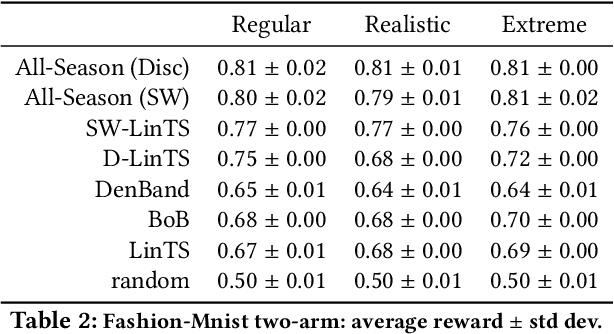
Contextual bandit algorithms are extremely popular and widely used in recommendation systems to provide online personalised recommendations. A recurrent assumption is the stationarity of the reward function, which is rather unrealistic in most of the real-world applications. In the music recommendation scenario for instance, people's music taste can abruptly change during certain events, such as Halloween or Christmas, and revert to the previous music taste soon after. We would therefore need an algorithm which can promptly react to these changes. Moreover, we would like to leverage already observed rewards collected during different stationary periods which can potentially reoccur, without the need of restarting the learning process from scratch. A growing literature has addressed the problem of reward's non-stationarity, providing algorithms that could quickly adapt to the changing environment. However, up to our knowledge, there is no algorithm which deals with seasonal changes of the reward function. Here we present a contextual bandit algorithm which detects and adapts to abrupt changes of the reward function and leverages previous estimations whenever the environment falls back to a previously observed state. We show that the proposed method can outperform state-of-the-art algorithms for non-stationary environments. We ran our experiment on both synthetic and real datasets.