 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRanker-agnostic Contextual Position Bias Estimation
Jul 28, 2021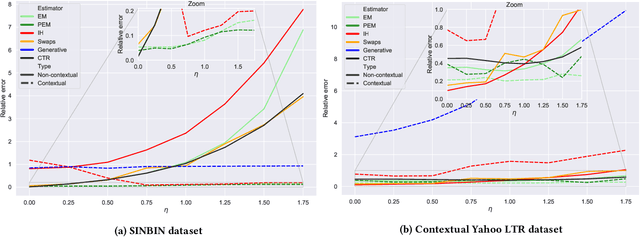

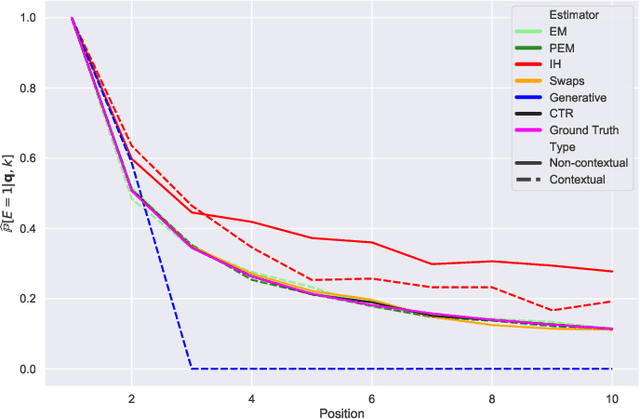

Learning-to-rank (LTR) algorithms are ubiquitous and necessary to explore the extensive catalogs of media providers. To avoid the user examining all the results, its preferences are used to provide a subset of relatively small size. The user preferences can be inferred from the interactions with the presented content if explicit ratings are unavailable. However, directly using implicit feedback can lead to learning wrong relevance models and is known as biased LTR. The mismatch between implicit feedback and true relevances is due to various nuisances, with position bias one of the most relevant. Position bias models consider that the lack of interaction with a presented item is not only attributed to the item being irrelevant but because the item was not examined. This paper introduces a method for modeling the probability of an item being seen in different contexts, e.g., for different users, with a single estimator. Our suggested method, denoted as contextual (EM)-based regression, is ranker-agnostic and able to correctly learn the latent examination probabilities while only using implicit feedback. Our empirical results indicate that the method introduced in this paper outperforms other existing position bias estimators in terms of relative error when the examination probability varies across queries. Moreover, the estimated values provide a ranking performance boost when used to debias the implicit ranking data even if there is no context dependency on the examination probabilities.
Affine-Invariant Robust Training
Oct 08, 2020



The field of adversarial robustness has attracted significant attention in machine learning. Contrary to the common approach of training models that are accurate in average case, it aims at training models that are accurate for worst case inputs, hence it yields more robust and reliable models. Put differently, it tries to prevent an adversary from fooling a model. The study of adversarial robustness is largely focused on $\ell_p-$bounded adversarial perturbations, i.e. modifications of the inputs, bounded in some $\ell_p$ norm. Nevertheless, it has been shown that state-of-the-art models are also vulnerable to other more natural perturbations such as affine transformations, which were already considered in machine learning within data augmentation. This project reviews previous work in spatial robustness methods and proposes evolution strategies as zeroth order optimization algorithms to find the worst affine transforms for each input. The proposed method effectively yields robust models and allows introducing non-parametric adversarial perturbations.
FastVC: Fast Voice Conversion with non-parallel data
Oct 08, 2020

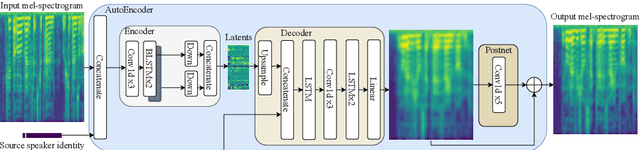
This paper introduces FastVC, an end-to-end model for fast Voice Conversion (VC). The proposed model can convert speech of arbitrary length from multiple source speakers to multiple target speakers. FastVC is based on a conditional AutoEncoder (AE) trained on non-parallel data and requires no annotations at all. This model's latent representation is shown to be speaker-independent and similar to phonemes, which is a desirable feature for VC systems. While the current VC systems primarily focus on achieving the highest overall speech quality, this paper tries to balance the development concerning resources needed to run the systems. Despite the simple structure of the proposed model, it outperforms the VC Challenge 2020 baselines on the cross-lingual task in terms of naturalness.