 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRanker-agnostic Contextual Position Bias Estimation
Paper and Code
Jul 28, 2021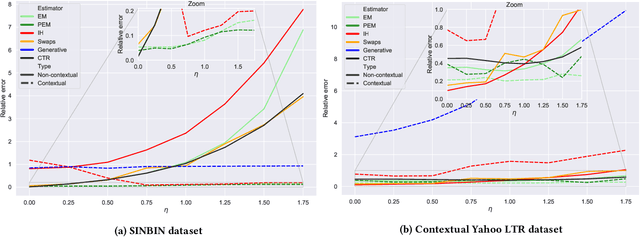

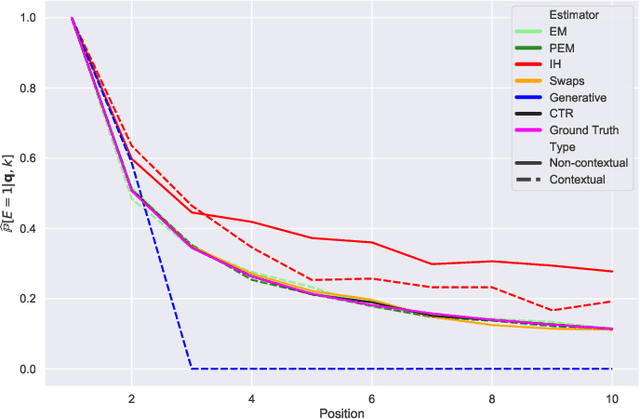

Learning-to-rank (LTR) algorithms are ubiquitous and necessary to explore the extensive catalogs of media providers. To avoid the user examining all the results, its preferences are used to provide a subset of relatively small size. The user preferences can be inferred from the interactions with the presented content if explicit ratings are unavailable. However, directly using implicit feedback can lead to learning wrong relevance models and is known as biased LTR. The mismatch between implicit feedback and true relevances is due to various nuisances, with position bias one of the most relevant. Position bias models consider that the lack of interaction with a presented item is not only attributed to the item being irrelevant but because the item was not examined. This paper introduces a method for modeling the probability of an item being seen in different contexts, e.g., for different users, with a single estimator. Our suggested method, denoted as contextual (EM)-based regression, is ranker-agnostic and able to correctly learn the latent examination probabilities while only using implicit feedback. Our empirical results indicate that the method introduced in this paper outperforms other existing position bias estimators in terms of relative error when the examination probability varies across queries. Moreover, the estimated values provide a ranking performance boost when used to debias the implicit ranking data even if there is no context dependency on the examination probabilities.