Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClustering Patients with Tensor Decomposition
Paper and Code
Aug 29, 2017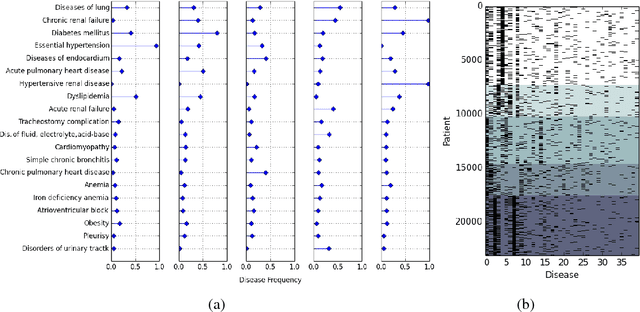



In this paper we present a method for the unsupervised clustering of high-dimensional binary data, with a special focus on electronic healthcare records. We present a robust and efficient heuristic to face this problem using tensor decomposition. We present the reasons why this approach is preferable for tasks such as clustering patient records, to more commonly used distance-based methods. We run the algorithm on two datasets of healthcare records, obtaining clinically meaningful results.
* Presented at 2017 Machine Learning for Healthcare Conference (MLHC
2017). Boston, MA
View paper on