 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating Synthetic but Plausible Healthcare Record Datasets
Jul 04, 2018
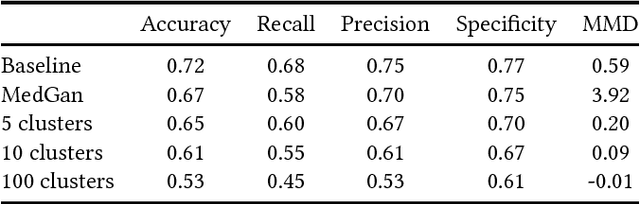
Generating datasets that "look like" given real ones is an interesting tasks for healthcare applications of ML and many other fields of science and engineering. In this paper we propose a new method of general application to binary datasets based on a method for learning the parameters of a latent variable moment that we have previously used for clustering patient datasets. We compare our method with a recent proposal (MedGan) based on generative adversarial methods and find that the synthetic datasets we generate are globally more realistic in at least two senses: real and synthetic instances are harder to tell apart by Random Forests, and the MMD statistic. The most likely explanation is that our method does not suffer from the "mode collapse" which is an admitted problem of GANs. Additionally, the generative models we generate are easy to interpret, unlike the rather obscure GANs. Our experiments are performed on two patient datasets containing ICD-9 diagnostic codes: the publicly available MIMIC-III dataset and a dataset containing admissions for congestive heart failure during 7 years at Hospital de Sant Pau in Barcelona.
Clustering Patients with Tensor Decomposition
Aug 29, 2017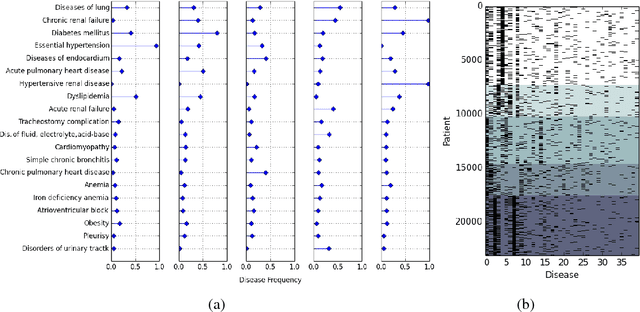



In this paper we present a method for the unsupervised clustering of high-dimensional binary data, with a special focus on electronic healthcare records. We present a robust and efficient heuristic to face this problem using tensor decomposition. We present the reasons why this approach is preferable for tasks such as clustering patient records, to more commonly used distance-based methods. We run the algorithm on two datasets of healthcare records, obtaining clinically meaningful results.
A New Spectral Method for Latent Variable Models
Apr 04, 2017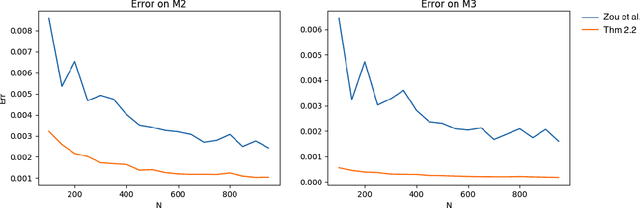

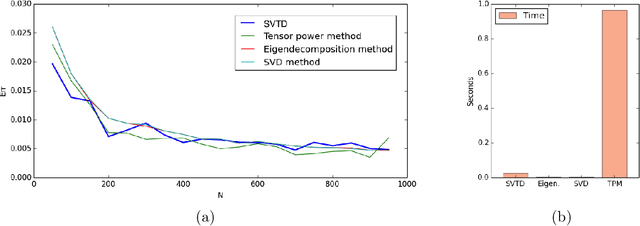

This paper presents an algorithm for the unsupervised learning of latent variable models from unlabeled sets of data. We base our technique on spectral decomposition, providing a technique that proves to be robust both in theory and in practice. We also describe how to use this algorithm to learn the parameters of two well known text mining models: single topic model and Latent Dirichlet Allocation, providing in both cases an efficient technique to retrieve the parameters to feed the algorithm. We compare the results of our algorithm with those of existing algorithms on synthetic data, and we provide examples of applications to real world text corpora for both single topic model and LDA, obtaining meaningful results.
Identifiability and Transportability in Dynamic Causal Networks
Oct 18, 2016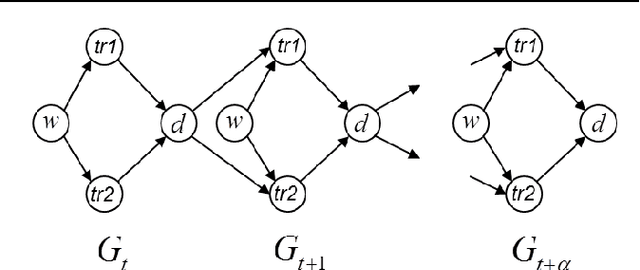
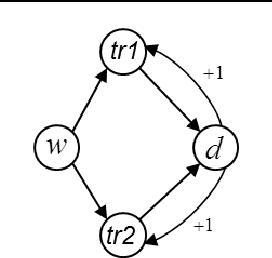
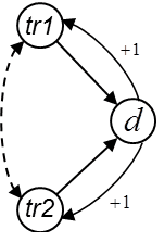
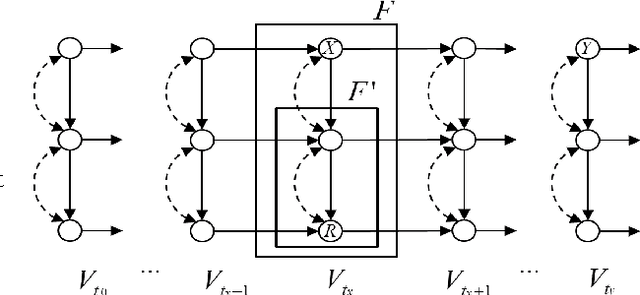
In this paper we propose a causal analog to the purely observational Dynamic Bayesian Networks, which we call Dynamic Causal Networks. We provide a sound and complete algorithm for identification of Dynamic Causal Net- works, namely, for computing the effect of an intervention or experiment, based on passive observations only, whenever possible. We note the existence of two types of confounder variables that affect in substantially different ways the iden- tification procedures, a distinction with no analog in either Dynamic Bayesian Networks or standard causal graphs. We further propose a procedure for the transportability of causal effects in Dynamic Causal Network settings, where the re- sult of causal experiments in a source domain may be used for the identification of causal effects in a target domain.