Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA New Spectral Method for Latent Variable Models
Paper and Code
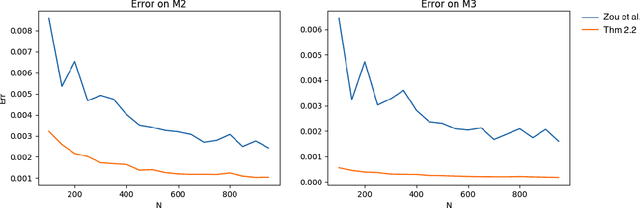

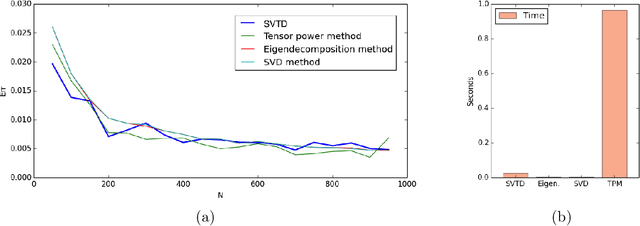

This paper presents an algorithm for the unsupervised learning of latent variable models from unlabeled sets of data. We base our technique on spectral decomposition, providing a technique that proves to be robust both in theory and in practice. We also describe how to use this algorithm to learn the parameters of two well known text mining models: single topic model and Latent Dirichlet Allocation, providing in both cases an efficient technique to retrieve the parameters to feed the algorithm. We compare the results of our algorithm with those of existing algorithms on synthetic data, and we provide examples of applications to real world text corpora for both single topic model and LDA, obtaining meaningful results.
View paper on