 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePOTEC: Off-Policy Learning for Large Action Spaces via Two-Stage Policy Decomposition
Paper and Code
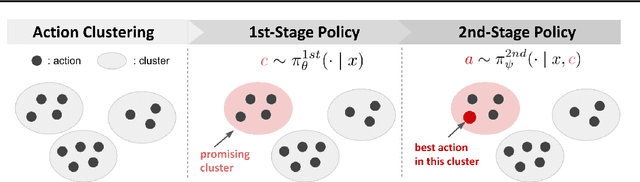

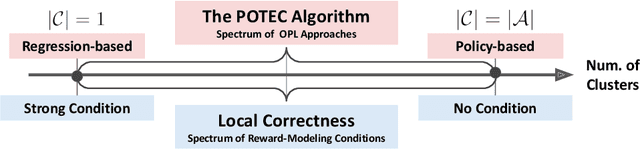

We study off-policy learning (OPL) of contextual bandit policies in large discrete action spaces where existing methods -- most of which rely crucially on reward-regression models or importance-weighted policy gradients -- fail due to excessive bias or variance. To overcome these issues in OPL, we propose a novel two-stage algorithm, called Policy Optimization via Two-Stage Policy Decomposition (POTEC). It leverages clustering in the action space and learns two different policies via policy- and regression-based approaches, respectively. In particular, we derive a novel low-variance gradient estimator that enables to learn a first-stage policy for cluster selection efficiently via a policy-based approach. To select a specific action within the cluster sampled by the first-stage policy, POTEC uses a second-stage policy derived from a regression-based approach within each cluster. We show that a local correctness condition, which only requires that the regression model preserves the relative expected reward differences of the actions within each cluster, ensures that our policy-gradient estimator is unbiased and the second-stage policy is optimal. We also show that POTEC provides a strict generalization of policy- and regression-based approaches and their associated assumptions. Comprehensive experiments demonstrate that POTEC provides substantial improvements in OPL effectiveness particularly in large and structured action spaces.